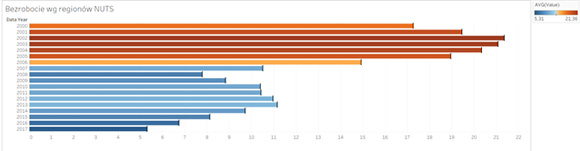
 Widzimy że bezrobocie maleje. Widzimy że jest dużo mniejsze niż przed (i po) kryzysem z 2008 roku. Widzimy też jak duże było ono na początku XXI wieku, jaka była skala problemu. Ale spróbujmy wykorzystać jeden drobiazg – taki guzik z napisem „Detail” w zakładce „Marks” w Tableau:
Widzimy że bezrobocie maleje. Widzimy że jest dużo mniejsze niż przed (i po) kryzysem z 2008 roku. Widzimy też jak duże było ono na początku XXI wieku, jaka była skala problemu. Ale spróbujmy wykorzystać jeden drobiazg – taki guzik z napisem „Detail” w zakładce „Marks” w Tableau:
 „Najedźmy” na niego interesującym nas poziomem szczegółowości – w tym przypadku identyfikatorem regionu, dla którego chcemy zbadać poziom tego zjawiska i zmieńmy sposób wizualizacji danych z wykresu słupkowego na „Circle”, czyli mój ulubiony wykres kropkowy. Później z zakładki „Analytics” dodajmy jeszcze linię referencyjną, oznaczającą średnią dla danego roku. Zobaczymy coś takiego:
„Najedźmy” na niego interesującym nas poziomem szczegółowości – w tym przypadku identyfikatorem regionu, dla którego chcemy zbadać poziom tego zjawiska i zmieńmy sposób wizualizacji danych z wykresu słupkowego na „Circle”, czyli mój ulubiony wykres kropkowy. Później z zakładki „Analytics” dodajmy jeszcze linię referencyjną, oznaczającą średnią dla danego roku. Zobaczymy coś takiego:
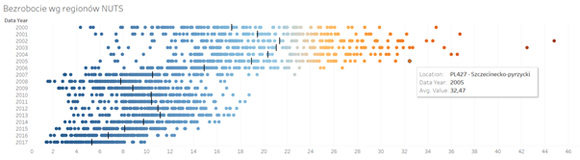 Zaczyna się robić ciekawie. Okazuje się, że bezrobocie rzeczywiście spada, ale w niektórych regionach … wcale go nie było. W apogeum Kryzysu, w 2009 roku, w Warszawie wynosiło ono … 2,5%, a w Poznaniu 2,6%. W tym samym czasie, w regionie szczecinecko – pyrzyckim skala problemu wynosiła 16,83% (a to i tak wielki spadek w porównaniu z rokiem 2002, gdy wyniosło ono 44,79%). Skądinąd widać niesamowity spadek bezrobocia w całej Polsce po roku 2003 i naszym wejściu do Unii Europejskiej – ciekawe, jak te dane korelują z liczbą mieszkańców poszczególnych regionów, którzy wyjechali za granicę… Ale to już temat na zupełnie inne rozważania.
Zauważmy jeszcze coś – położenie linii referencyjnej, oznaczającą średnią dla danego roku. De facto obrazuje ona sytuację w jednym, może dwóch regionach… Tyle warte jest patrzenie na średni poziom wskaźnika bez szerszego kontekstu.
Ale dołóżmy do naszych rozważań jeszcze coś – pokażmy te dane na mapie:
Zaczyna się robić ciekawie. Okazuje się, że bezrobocie rzeczywiście spada, ale w niektórych regionach … wcale go nie było. W apogeum Kryzysu, w 2009 roku, w Warszawie wynosiło ono … 2,5%, a w Poznaniu 2,6%. W tym samym czasie, w regionie szczecinecko – pyrzyckim skala problemu wynosiła 16,83% (a to i tak wielki spadek w porównaniu z rokiem 2002, gdy wyniosło ono 44,79%). Skądinąd widać niesamowity spadek bezrobocia w całej Polsce po roku 2003 i naszym wejściu do Unii Europejskiej – ciekawe, jak te dane korelują z liczbą mieszkańców poszczególnych regionów, którzy wyjechali za granicę… Ale to już temat na zupełnie inne rozważania.
Zauważmy jeszcze coś – położenie linii referencyjnej, oznaczającą średnią dla danego roku. De facto obrazuje ona sytuację w jednym, może dwóch regionach… Tyle warte jest patrzenie na średni poziom wskaźnika bez szerszego kontekstu.
Ale dołóżmy do naszych rozważań jeszcze coś – pokażmy te dane na mapie:
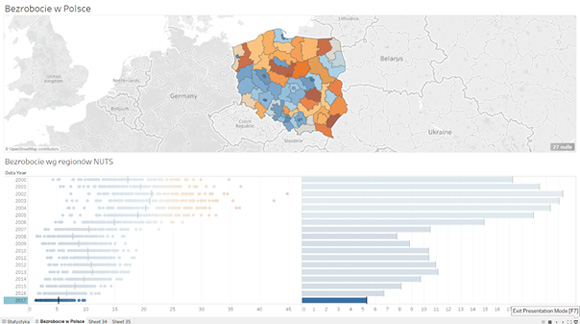 Widzimy od razu GDZIE mamy rzeczywisty problem i GDZIE powinna się skoncentrować pomoc publiczna, rządowa, pieniądze na aktywizację, budowę infrastruktury, przyciąganie inwestorów, pomoc publiczną itp. Jeżeli uznalibyśmy, że problem bezrobocia dotyczy regionów, gdzie przekracza ono 8%, to mapa bezrobocia w Polsce wygląda teraz tak:
Widzimy od razu GDZIE mamy rzeczywisty problem i GDZIE powinna się skoncentrować pomoc publiczna, rządowa, pieniądze na aktywizację, budowę infrastruktury, przyciąganie inwestorów, pomoc publiczną itp. Jeżeli uznalibyśmy, że problem bezrobocia dotyczy regionów, gdzie przekracza ono 8%, to mapa bezrobocia w Polsce wygląda teraz tak:
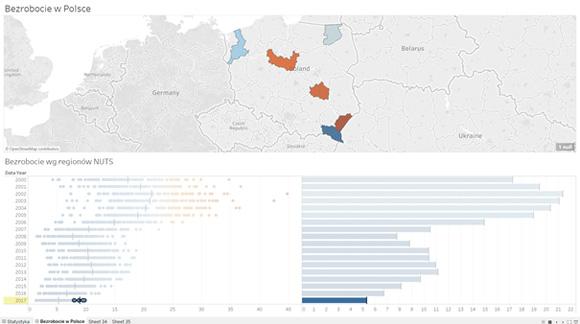 Zapewne jeszcze ciekawsze dane można znaleźć schodząc do poziomu poszczególnych gmin, czy powiatów – wtedy wnioski mogą być dużo bardziej trafne. Ważne jest to, że widać dużo więcej, niż w przypadku danych zagregowanych.
Zastosowań tego typu podejścia do analiz może być znacznie więcej – choćby porównanie zyskowności poszczególnych grup asortymentowych do poziomu produktów:
Zapewne jeszcze ciekawsze dane można znaleźć schodząc do poziomu poszczególnych gmin, czy powiatów – wtedy wnioski mogą być dużo bardziej trafne. Ważne jest to, że widać dużo więcej, niż w przypadku danych zagregowanych.
Zastosowań tego typu podejścia do analiz może być znacznie więcej – choćby porównanie zyskowności poszczególnych grup asortymentowych do poziomu produktów:
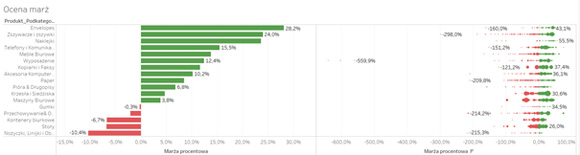 Tutaj widzimy jeszcze więcej, gdyż wykorzystując atrybut „Size” w zakładce „Marks” pokazałem skalę problemu – tzn. być może nie należy się martwić ujemną marżą procentową na zadanym produkcie, gdy wolumen jego sprzedaży jest niewielki, lepiej skoncentrować się tam, gdzie uciekają naprawdę większe pieniądze, jak tutaj:
Tutaj widzimy jeszcze więcej, gdyż wykorzystując atrybut „Size” w zakładce „Marks” pokazałem skalę problemu – tzn. być może nie należy się martwić ujemną marżą procentową na zadanym produkcie, gdy wolumen jego sprzedaży jest niewielki, lepiej skoncentrować się tam, gdzie uciekają naprawdę większe pieniądze, jak tutaj:
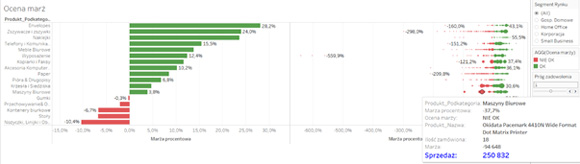 No właśnie – uciekają pieniądze. I tu dochodzimy do tego PO CO warto patrzeć na dane w taki sposób i co daje taka ich syntetyczna prezentacja z natychmiastową możliwością zejścia do nisko położonych szczegółów… Jeśli zestawimy koszt wdrożenia takiego narzędzia i podejścia do pracy z danymi, jakie proponujemy, ze skalą ewentualnych korzyści, to zwrot z takiej inwestycji może być naprawdę kolosalny – i tutaj widać czym różni się WIZUALNA ANALIZA DANYCH od samej WIZUALIZACJI DANYCH… Polecam to Państwa uwadze…
Witold Kilijański
Partner
NewDataLabs
No właśnie – uciekają pieniądze. I tu dochodzimy do tego PO CO warto patrzeć na dane w taki sposób i co daje taka ich syntetyczna prezentacja z natychmiastową możliwością zejścia do nisko położonych szczegółów… Jeśli zestawimy koszt wdrożenia takiego narzędzia i podejścia do pracy z danymi, jakie proponujemy, ze skalą ewentualnych korzyści, to zwrot z takiej inwestycji może być naprawdę kolosalny – i tutaj widać czym różni się WIZUALNA ANALIZA DANYCH od samej WIZUALIZACJI DANYCH… Polecam to Państwa uwadze…
Witold Kilijański
Partner
NewDataLabs

