Narzędzia self-service BI z definicji powinny zapewniać użytkownikowi samodzielną pracę z danymi. Oznacza to nie tylko warstwę analityczną i wizualno-prezentacyjną, ale również modelującą dane przed właściwym procesem analitycznym. W końcu stare analityczne porzekadło mówi, że analitycy 80% czasu poświęcają na zbieranie, przygotowywanie i obrabianie danych, a jedynie 20% na właściwą analizę i wizualizację. Producenci oprogramowania Business Intelligence oczywiście zdają sobie z tego sprawę – stąd swoje flagowe produkty self service BI uzupełniają dodatkami ETL.
ETL – co to takiego?
Extract Transform and Load – czyli pozyskanie, przekształcenie i załadowanie danych. Stanowi jeden z podstawowych elementów procesów Business Intelligence. W końcu aby analizować dane, musimy je po pierwsze pozyskać, następnie przekształcić do odpowiedniej formy, załadować do docelowego środowiska aby w końcu móc je analizować i wizualizować.
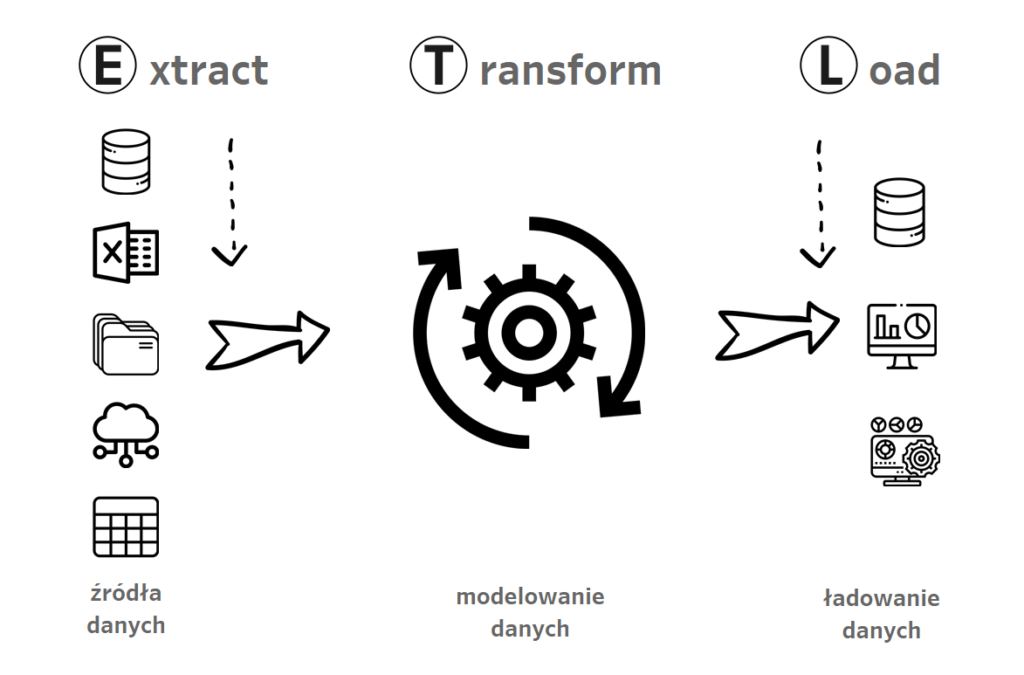
Poszczególne fazy oznaczają:
Extract – pozyskujemy dane z baz danych, hurtowni, data lake’ów, chmury, pliki, tabele
Transform – przetwarzamy dane, aby móc je analizować: czyszczenie, filtrowanie, łączenie tabel etc
Load – ładowanie do docelowego środowiska: aplikacje BI, ale również w razie potrzeby ponownie bazy, hurtownie, tabele
Dodatki ETL, jako część pakietu self service BI
Koncept narzędzi ETL sięga lat siedemdziesiątych i rozwijał się równolegle z koncepcjami relacyjnych baz danych. Jednym z pierwszym przykładów języków funkcjonujących jako ETL jest SQL, czyli Structured Query Language – język zapytań do baz danych. Przez te lata oczywiście wiele się zmieniło, i aby móc modelować dane nie potrzebujemy znać języków programowania (chociaż Python czy R ma tutaj swoje zastosowanie). Aplikacje ETL umożliwiają poprzez graficzny interfejs przeprowadzać transformacje danych do odpowiedniej postaci. Ostatnie lata to również intensywny rozwój narzędzi do wizualizacji danych, a ich producenci chcąc dostarczyć użytkownikom jak najbardziej kompleksowy produkt zawierają w ich ramach również dodatki ETL. W przypadku Tableau jest to Tableau Prep, a w przypadku Power BI – Power Query. Oba programy są częścią licencji dla developerów, więc nie generują dodatkowych kosztów. Fakt ten plus integracja z narzędziami wizualnymi powodują, że warto pochylić się nad ich funkcjonalnościami i możliwościami zastosowania w naszej organizacji.

Tableau Prep – wizualizacja przepływu danych
Tableau Prep oferuje podobny interfejs jak Tableau – więc na początku poczujemy się jak w domu. W zakresie dostępnych rodzajów połączeń mamy dostępny szeroki wachlarz możliwości – od plików csv czy xls, przez hurtownie, data lake’i po rozwiązania chmurowe. Prawdziwa magia Prepa objawia się po podłączeniu danych i stworzeniu przepływu danych:
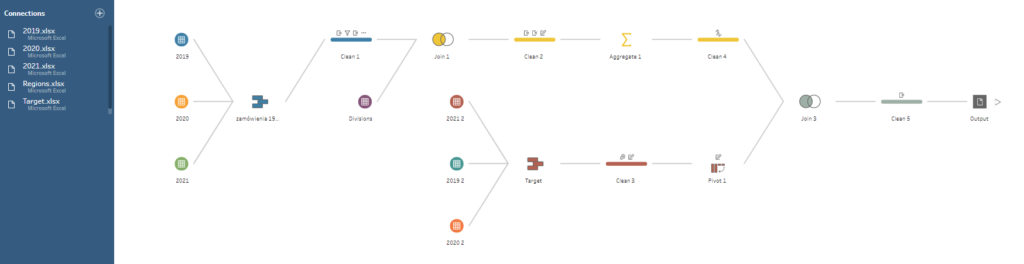
Każdy element na diagramie przypływu oznacza jeden element składowy danego procesu ETL.
Extract – źródła danych dodajemy z panelu Connections, a na diagramie mają ikonkę ![]()
Transform – tutaj dostępny mamy szereg możliwości przy dodaniu nowego kroku:

– clean: filtrowanie, zamiana, typy danych, pola kalkulowane, usuwanie, dodawanie kolumn, działania na danych etc
– aggregate: grupowanie miar według zadanych wymiarów (np. mając dane sprzedażowe po dniach, możemy dodać agregacje po miesiącach)
– pivot: zamiana kolumn na wiersze i na odwrót
– join: dołączanie tabel (left, inner, right, outer, etc)
– union: łączenie table jedna pod drugą (np. konsolidacja plików o takiej samej strukturze)
– script: wywołanie skryptu Pythona
– prediction: wywołanie predykcji Einstein Analytics
Jak widać Prep to nie tylko czyszczenie danych, ale również bardziej zaawansowane zastosowania dzięki obsłudze skryptów Pythona czy Einstein Analytics. Dzięki temu kwestie machine learning stoją również dla nas otworem.
Flow w Tableau Prep, a elementy ETL
Dekomponując przykładowy flow widzimy poszczególne elementy procesu ETL:
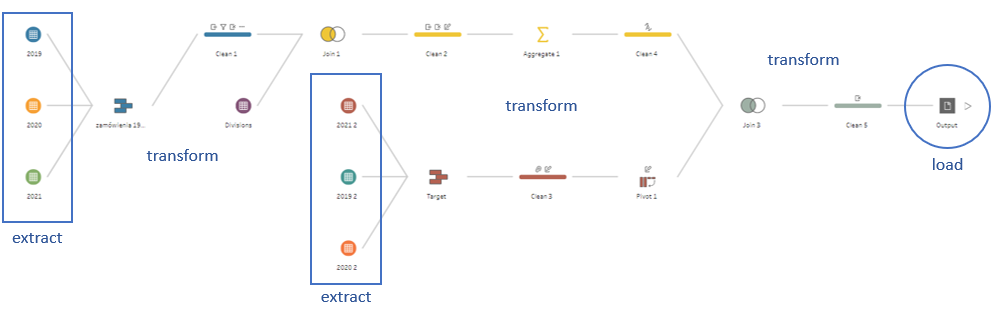
Widać tutaj również, że ETL nie jest procesem ze sztywną strukturą. Poszczególne elementy mogą się przenikać, a efekt jednych przekształceń (load) może być wsadem do następnych (extract).
Interfejs Tableau Prepa jest bardzo funkcjonalny, natomiast początkowo może być wymagać nieco czasu do przyzwyczajenia się. Tableau stawia na przekaz wizualny i na każdym etapie widzimy co dokładnie dzieje się z naszymi danymi.
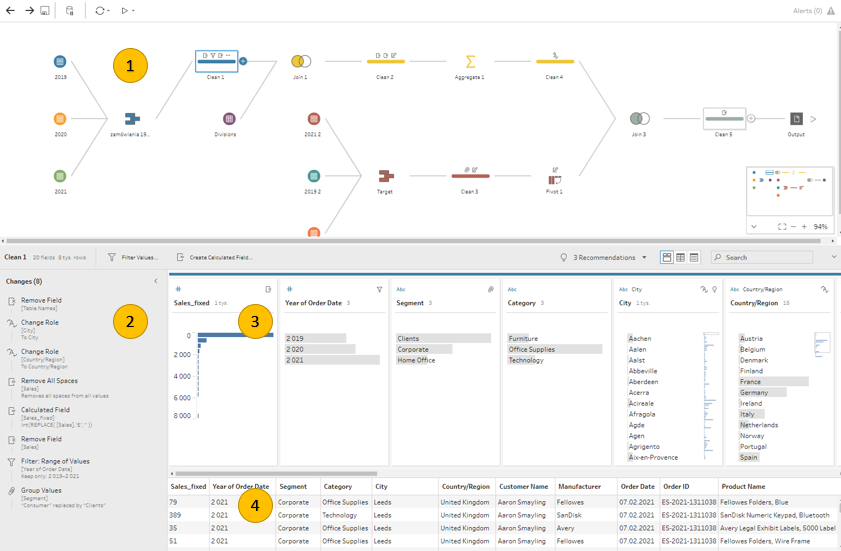
Poniżej widać szczegółowy widok kroku ‘clean’, czyli czyszczenia danych. Na górze (1) mamy cały czas podgląd na nasz przepływ i widzimy, który krok aktualnie tworzymy. Na dole widzimy:
– panel zmian (2), które wprowadziliśmy w danych (takie jak filtrowanie, usunięcie kolumn, pola kalkulowane)
– podsumowanie kolumn w naszych danych (3) – typ danych, podsumowanie wartości wraz z wykresami
– surowe dane (4) – tabela z podglądem przetworzonych danych
Oczywiście każdy krok posiada nieco inny interfejs – przykładowo krok Join wygląda następująco:
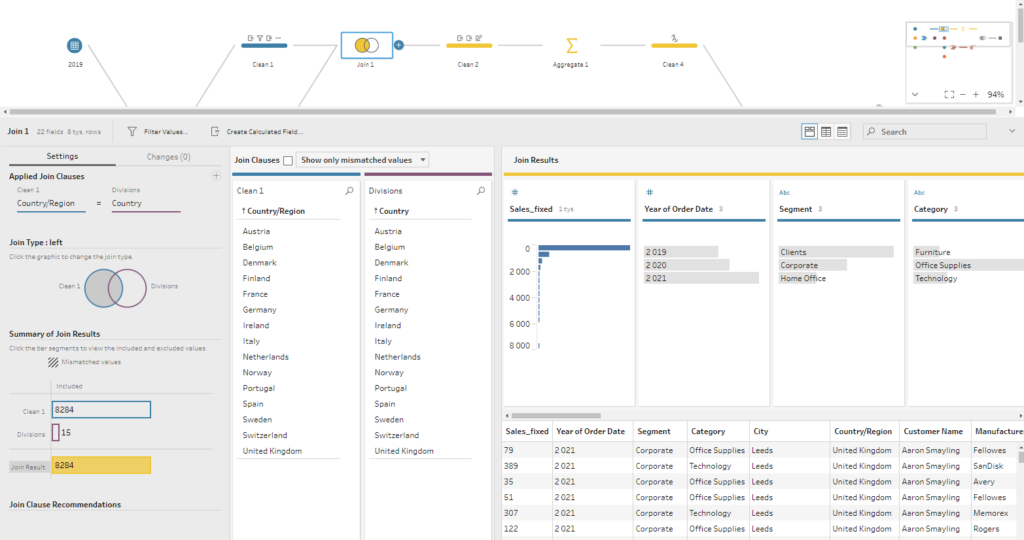
Wszelkie przekształcenia kończy krok Output, którzy odpowiada fazie Load procesu ETL. Dane możemy załadować do pliku (xls, csv, hyper), do opublikowane źródła danych na Tableau Server lub dopisać do bazy/hurtowni danych:
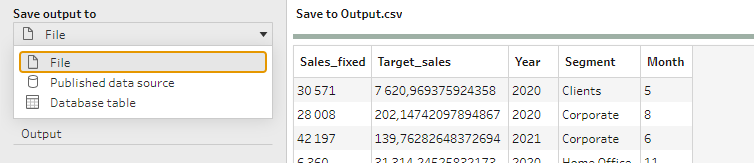
W kolejnej części wpisu przyjrzymy się bliżej PowerQuery i podsumowaniu obu narzędzi.
Mateusz Karmalski, Tableau Author


