Architektura hurtowni danych to system, który definiuje sposób w jaki prezentowane i przetwarzane są dane w repozytorium. Repozytoria można podzielić ze względu na podejście do danych, czyli na tradycyjne oraz nowoczesne. System chmurowy pomaga na uzupełnianiu luk, które pojawiają się w starszych bazach danych. Architektura hurtowni danych w Snowflake jest zaprojektowana natywnie. Co oznacza, że użytkownicy pracują na bazie danych bezpośrednio, bez pomocy dodatkowych programów, czy aplikacji. Została połączona z innowacyjnym silnikiem zapytań SQL.
Architektura trójwarstwowa w Snowflake.
Architektura Snowflake jest połączeniem tradycyjnej architektury współdzielonego dysku i współdzielonej architektury baz danych. Są one dostępne ze wszystkich węzłów obliczeniowych platformy. Architektura podzielona jest na trzy warstwy.
- Cloud services – usługa w chmurze.
Warstwa, która zarządza optymalizacją zapytań, kontrolą dostępu, infrastrukturą, metadanymi oraz optymalizuje zapytania do momentu otrzymania wyników. Usługi w celu przetwarzania żądań użytkowników łączą różne komponenty aplikacji.
- Query processing – przetwarzanie zapytań.
Dzięki dostępowi do virtual warehouse, czyli wirtualnego magazynu, możliwe jest przetwarzanie zapytań. Wirtualny magazyn jest klastrem obliczeniowym MPP. Składa się z wielu węzłów obliczeniowych, które przydziela Snowflake od dostawcy chmury. Natomiast wirtualna hurtownia jest niezależnym klastrem obliczeniowy. Ta zależność pozwala na nie zakłócanie wydajności wirtualnych magazynów przez wirtualne hurtownie.
- Database storage – przechowywanie baz danych.
Warstwa odpowiedzialna jest za przechowywanie danych w chmurze w wewnętrznym formacie kolumnowym. Dane, które się tu znajdują są domyślnie skompresowane. W przypadku Snowflake, to system odpowiedzialny jest za zarządzanie metadanymi (organizacja, rozmiar pliku, kompresja, struktura, statystyki). Twórcy dashboardów bezpośrednio nie widzą i nie mają dostępu do obiektów danych, które przechowywane są w Snowflake. Uzyskują oni dostęp tylko za pośrednictwem operacji zapytań SQL, które są uruchamiane za pomocą narzędzia.
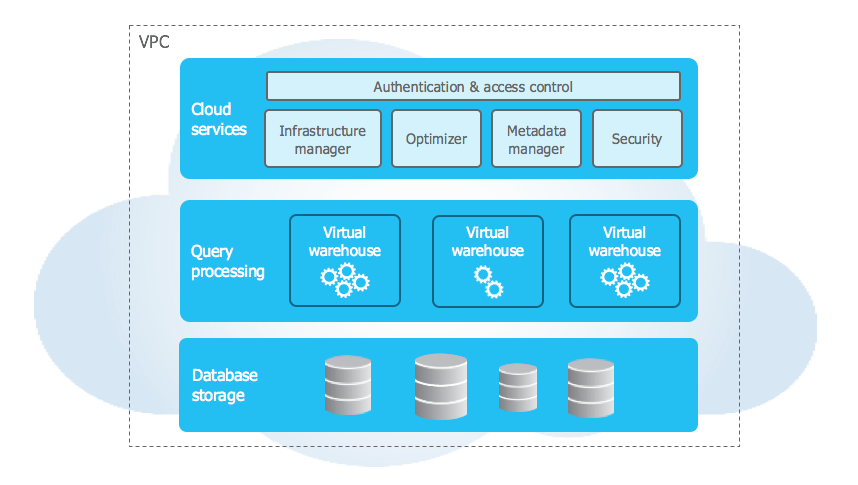
Architektura danych w Snowflake
Źrodło: snowflake.com
Jak Data Cloud firmy Snowflake rozwiązuje problemy związane z pozyskiwaniem danych?
Pozyskiwanie danych dzieli się na dwa rodzaje: strumieniowanie danych (data streaming) oraz pozyskiwanie danych w partiach (które czasem wymaga procesu ETL lub ELT). Strumieniowe przesyłanie danych odbywa się w czasie rzeczywistym nawet jeśli nie mamy określonego harmonogramu. Pozyskiwanie danych w partiach odbywa się poprzez importowanie danych w oddzielnych porcjach w precyzyjniej określonych przedziałach czasowych. Efektywny proces pozyskiwania danych należy rozpocząć od ustalenia priorytetów źródeł danych. Następnie należy sprawdzić poprawności plików oraz skierować elementy danych do odpowiedniego miejsca docelowego.
Częstym problem firm przy pozyskiwaniu danych, jest zbyt długi czas oczekiwania na uzyskanie interesującej informacji. Problemem może się okazać zbyt duża ilość danych, które próbujemy przetworzyć, niezgodne formaty danych, dane pochodzące z wielu źródeł. Narzędzie Snowflake podchodzi do danych w sposób holistyczny, co oznacza, że skupia się na sposobie ich integracji i analizie, które zapewniają maksymalny wgląd w działalność biznesową.
Snowflake i Big Data.
Narzędzie Snowflake to idealne rozwiązanie dla firm, które potrzebują integracji ustrukturyzowanych i częściowo ustrukturyzowanych danych, aby móc dzięki temu uzyskać wiarygodną analizę biznesową przedsiębiorstwa. Narzędzie automatyzuje i zwiększa możliwość pozyskiwania danych z różnych źródeł, ponieważ zasoby obliczeniowe są łatwo dostosowywane do Big Data.
Jeżeli chcielibyście się dowiedzieć więcej na temat jednego z najbardziej wydajnych narzędzi Big Data w chmurze i pobrać bezpłatnie trial, zapraszam na stronę https://newdatalabs.com/snowflake/.


