Wizualizacja rozkładu danych. Na wczesnym etapie analizy istotne jest zrozumienie, z jakimi danymi mamy do czynienia. Czy są to wartości liczbowe czy opisowe? Które zmienne są istotne? I jak wygląda rozkład tych wartości? Zwłaszcza ten ostatni element jest istotny do lepszego zrozumienia danych. Pozwala on znaleźć odpowiedź na szereg istotnych pytań – jaki jest zakres wartości zmiennych? Jak one się rozkładają? Czy rozkład jest symetryczny? Czy pewne cechy są dominujące, czy występują znaczne wartości odstające? Odpowiedzi na te pytania pozwalają nam budować wiedzę na temat danych, z którymi się mierzymy. Jak ułatwić sobie zrozumienie rozkładów zmiennych przy wykorzystaniu wizualizacji danych?
Używamy histogramu do analizy zmiennych numerycznych
Histogram jest specyficznym rodzajem bar chartu, gdzie na osi Y mamy licznik wartości, a na osi X kategorie lub przedziały danej wartości numerycznej. Wykres ten w Tableau tworzymy bardzo prosto – wystarczy przenieść żądaną miarę na wykres, a dostępna staje się opcja Histogram w Show me:
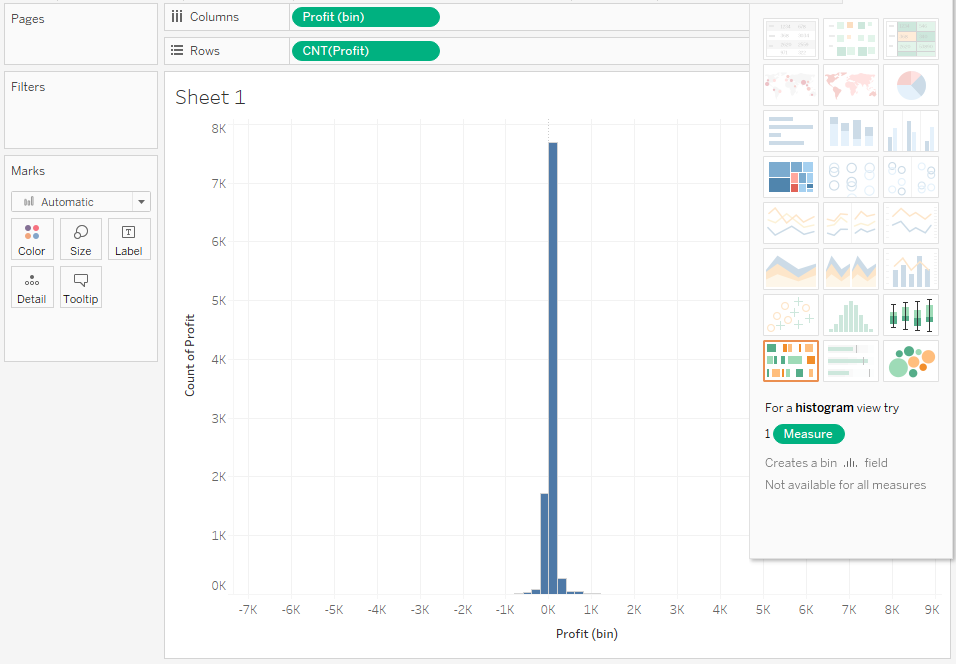
Jak to zwykle bywa, wykres stworzony poprzez Show me wymaga nieco pracy. Zacznijmy od interpretacji samego wykresu. Rozkład wygląda na symetryczny, ale nieco rozciągnięty z obu stron. Wskazuje to istnienie wartości odstających (outliers), które zaburzają nieco odbiór. Są przy tym na tyle małe, że nawet nie widać ich na wykresie. Spróbujmy pozbyć się tych wartości, zmniejszając zakres zmiennej Profit:
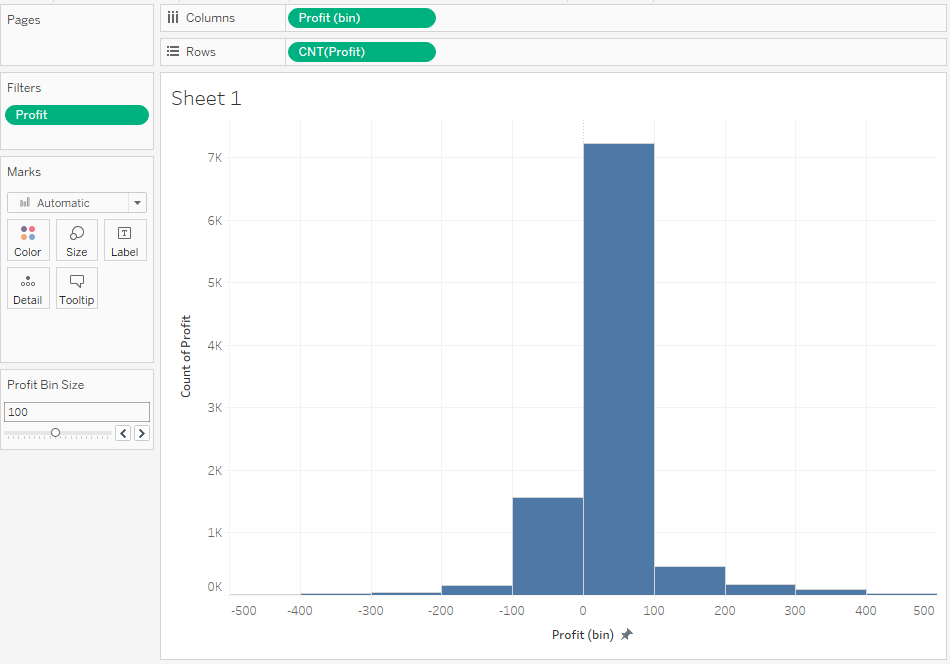
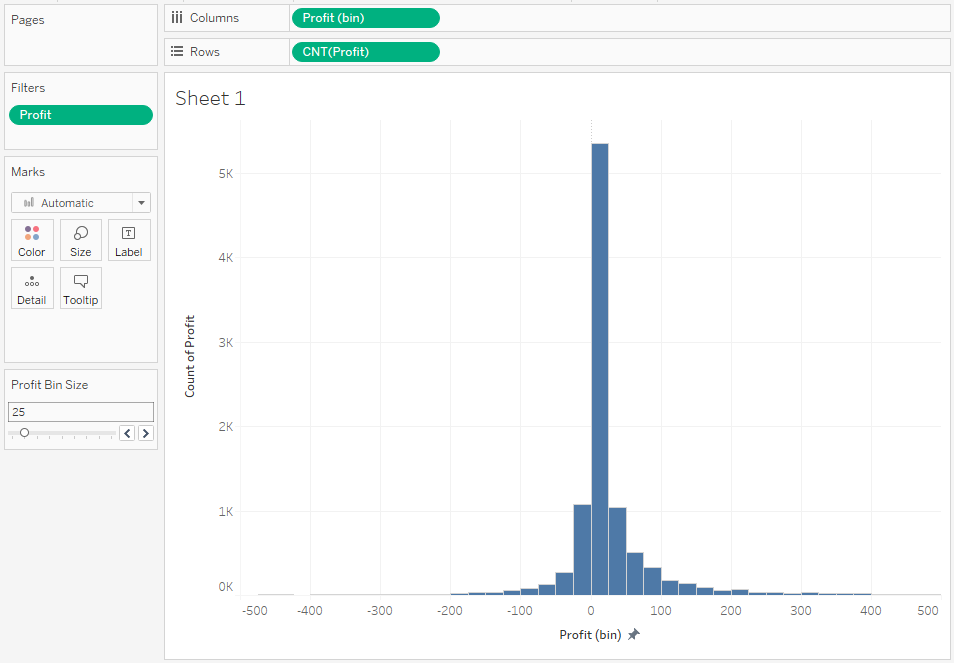
Jak widać większość wartości wpada w przedział 0-100. Możemy zmniejszyć rozmiar bin na osi X, aby lepiej poznać rozkład zmiennej w zakresie blisko 0:
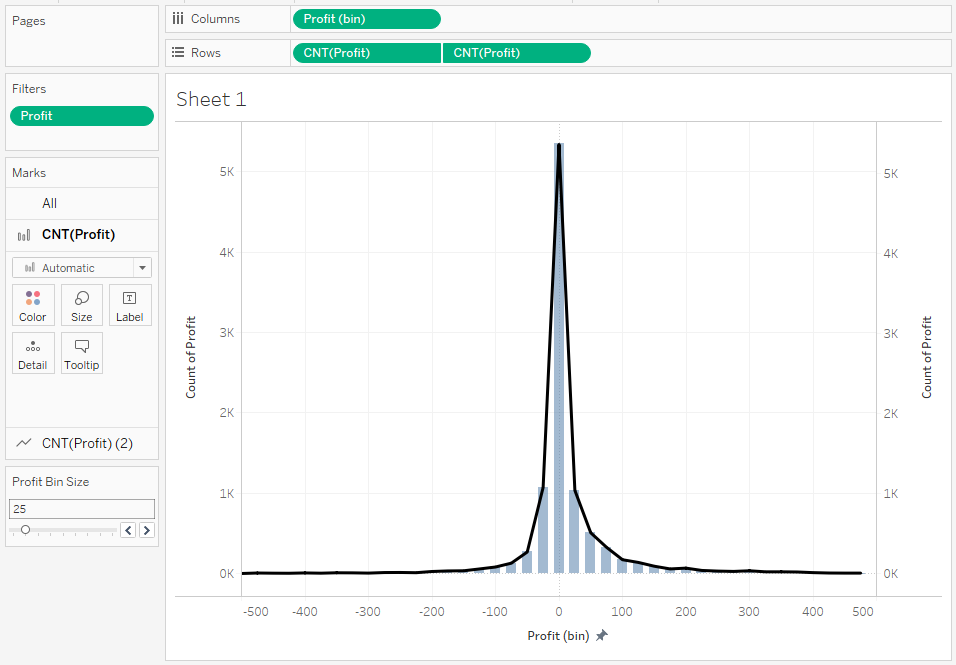
Histogram możemy również analizować w postaci line chart lub area chart, nakładając drugą oś z wykresem liniowym lub obszarowym:
Rozkład zmiennych dla kategorii
Spróbujmy analizy dystrybucji dla lepszego zrozumienia kategorii. Załóżmy, że chcemy poznać rozkład zysku wg kategorii Region i State:
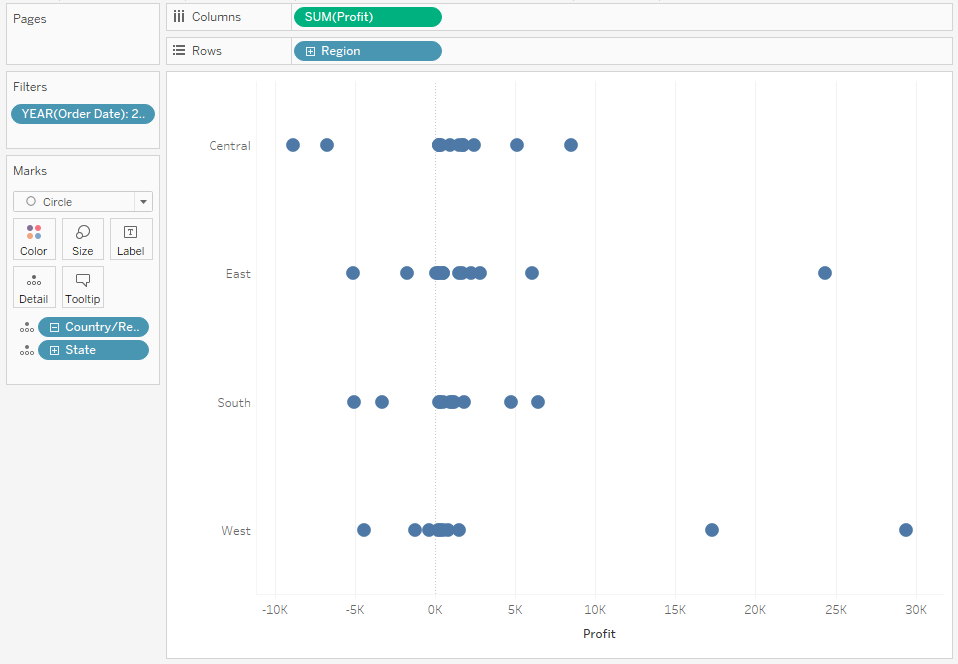
Problematyczne w tym podejściu jest to, że poszczególne punkty się na siebie nakładają, utrudniając zrozumienie gdzie występuje koncentracja danych. Możemy to rozwiązać poprzez zmniejszenie Opacity:
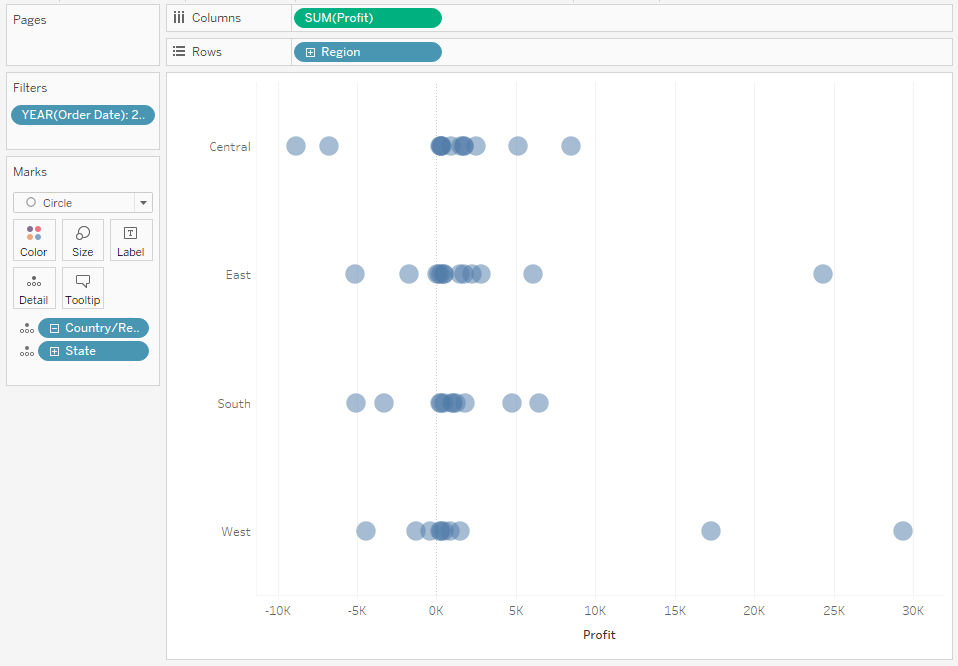
Jeżeli nadal czytelność nie jest dość dobra, to możemy powyższy dot plot zmienić na jitter plot, poprzez dodanie losowej dystrybucji punktów danych w ramach danej kategorii:
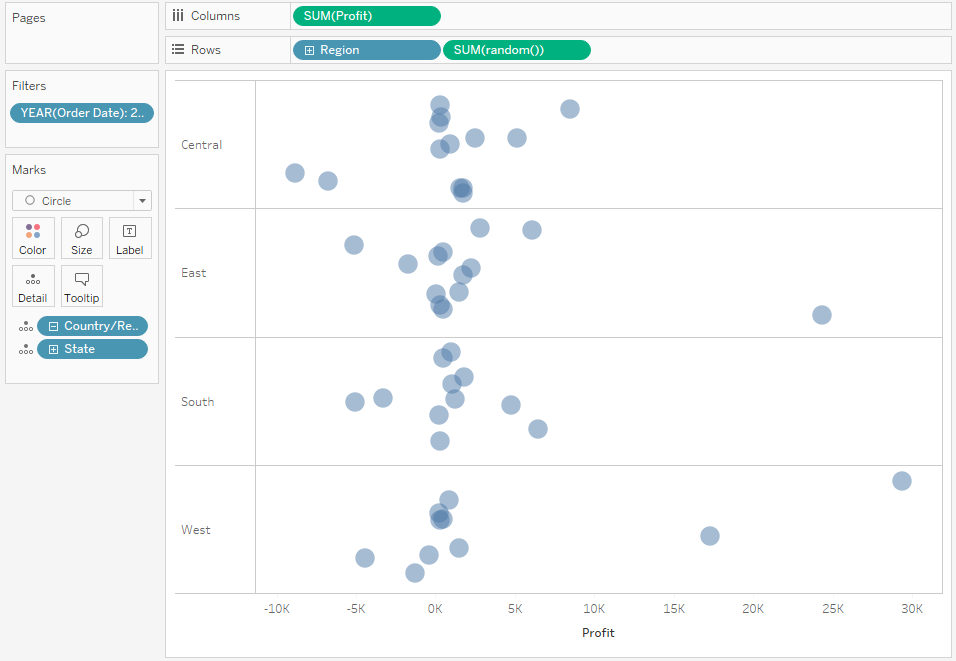
Dzięki temu zabiegowi łatwiej jest zidentyfikować punkty danych, ponieważ ich nakładanie jest ograniczone. Ale może rodzić to dodatkowe pytania – głównie o to, co jest na osi Y. Odbiorcy z reguły będą dopatrywać się dodatkowego znaczenia pozycji pionowej danego punktu danych, podczas gdy jest to tylko losowa nic nie znacząca liczba.
Jeżeli punktów jest dużo – używamy Box Plot
W sytuacji bardzo dużej ilości punktów danych wyciągnięcie wniosków na podstawie dot plot albo jitter plot może być trudne. Wtedy warto sięgnąć po wykres pudełkowy, czyli Box Plot – technikę wizualizacji pozwalającą na prezentację statystyk zbioru punktów:
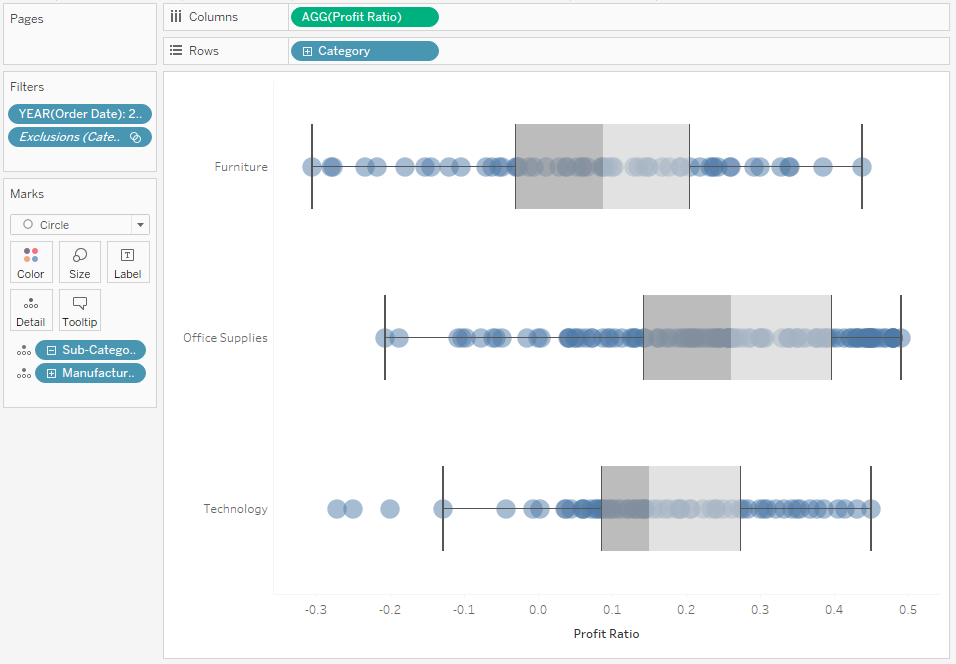
Jak interpretować box plot? Główny punkt to mediana, od której odmierzane są percentyle: 25 i 75. Obszar pomiędzy nimi to box, a linia w środku (dzieląca box na dwie części) to właśnie mediana. Kolejnym elementem są wąsy, wskazujące wartość najmniejszą i największą w zbiorze, jednak z zaznaczeniem, że odległość nie jest większa niż 1.5 razy rozstęp pomiędzy percentylami 25 i 75 (tzw. rozstęp ćwiartkowy – czyli szerokość pudełka). Wszelkie wartości poza wąsami są traktowane jako wartości odstające – outliers:
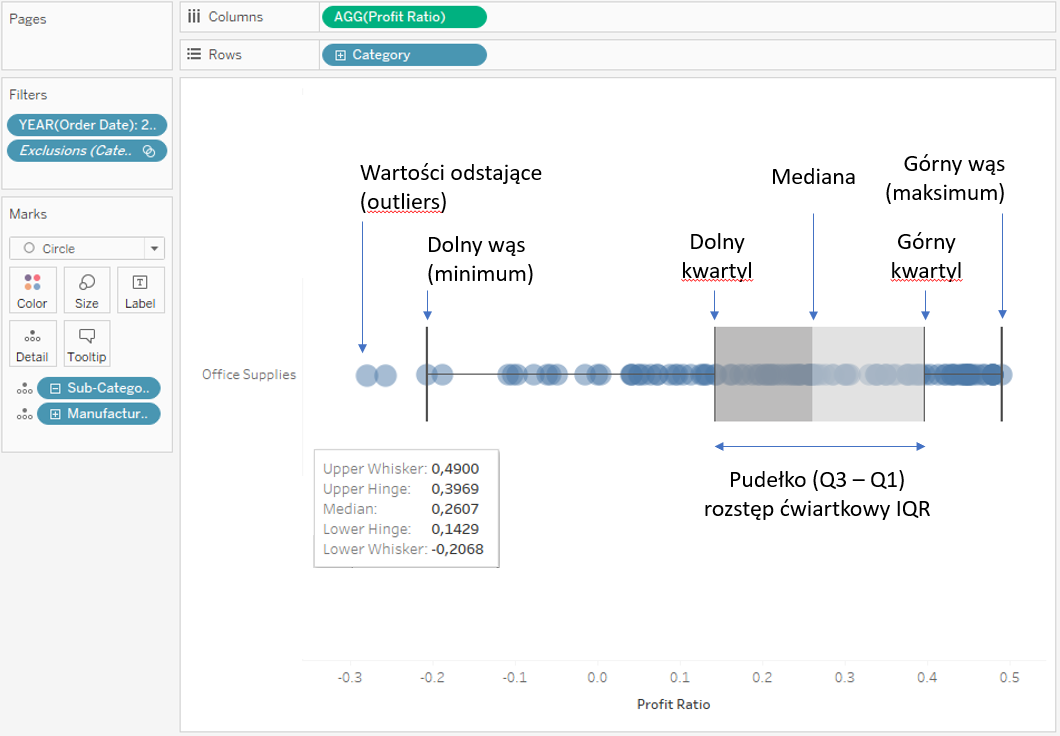
Box plot jest użyteczną techniką wizualizacji zbiorów danych. Należy jednak pamiętać, że nie każdy odbiorca zna jego interpretację. Dlatego stosując ten wykres, należy zawsze zastosować odpowiednie oznaczenia aby uniknąć błędnej interpretacji.
Rozkład zmiennej wg kilku kategorii
Dotychczas wizualizowaliśmy rozkład jednej zmiennej numerycznej i według jednego wymiaru. Jeżeli chcemy zbadać rozkład wg dwóch cech kategorialnych, możemy posłużyć się heat mapą – inaczej highlight table. Rozbudowując tabelę o wykresy bar chart z boków tabeli, uzyskujemy dodatkowy aspekt analizy poprzez porównanie wartości skumulowanych:

Jest to bardzo użyteczny sposób rozbudowania często popularnych wśród użytkowników tabel o dodatkowe aspekty wizualne.
Innym zastosowaniem jest zbadanie rozkładu dwóch zmiennych numerycznych jednocześnie. W przypadku dużej ilości punktów danych daje to podgląd obrazu ich dystrybucji. W poniższym przykładzie wykres główny to scatterplot, rozbudowany o marginal histograms:
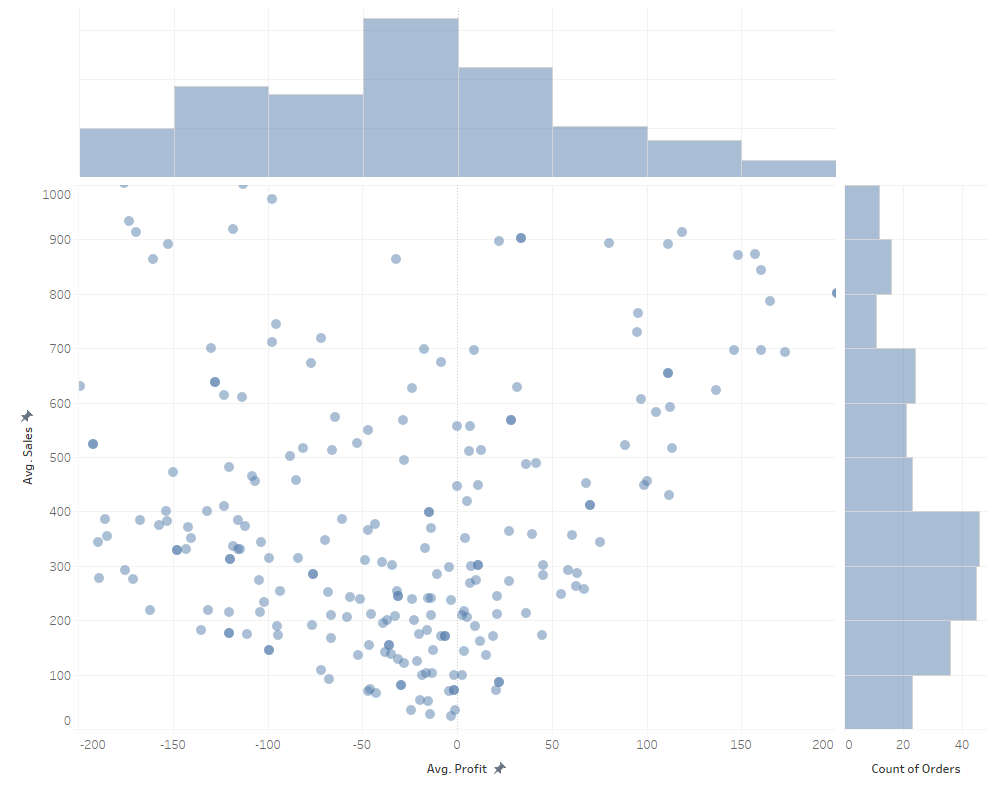
Wizualizacja rozkładu jest zawsze uproszczeniem
Rozkład danych ma dostarczyć nam informacji zbiorczych o danych: jaki zakres wartości obejmuje, jaka jest zmienność, czy rozkład jest symetryczny, które wartości występują najczęściej, czy są wartości odstające. Z uwagi na dużą liczbę punktów danych, takie zbiorcze podejście jest najczęściej najbardziej słusznym – pokazanie wszystkich obserwacji może przytłoczyć odbiorcę i być nieczytelnym i przez to również nieużytecznym. Powyższe techniki nie wyczerpują całości dostępnych technik wizualizacji – ale są najbardziej użyteczne i łatwe zarówno w przygotowaniu jak i odbiorze. Poza nimi można spotkać przykładowo wykres beeswarm – podobnie do jitter plot, ale punkty danych są rozkładane równomiernie. Innym rozwiązaniem jest violin chart – wykre skrzypcowy, który łączy ze sobą histogram w postaci area chart z box plotem. Jak widać opcji jest dużo, ale najlepiej kierować się prostotą i użytecznością, pamiętając o finalnym odbiorcy naszej wizualizacji.
Mateusz Karmalski Tableau Author


