W poprzednich wpisach z serii omówiliśmy podstawy obróbki danych w Tableau Prep. Zaczęliśmy od ładowania danych, następnie je oczyszczaliśmy i poddawaliśmy różnym transformacjom: grupowaniu, dzieleniu (split) czy filtrowaniu. Poznaliśmy również tworzenie pól obliczeniowych. W poniższym, ostatnim wpisie z serii, poznamy kolejne metody transformacji: agregację, transpozycję (pivot) oraz łączenie danych. Na koniec omówimy eksport danych w celu dalszej, wizualnej analizy już w Tableau Desktop. Wspomnimy również co jeszcze jest możliwe przy wykorzystaniu Prepa, mając na uwadze jego wykorzystanie jako narzędzia codziennej pracy analityka.
Agregacja danych
W sytuacji gdy nasze dane są w zbyt szczegółowej formie niż tego potrzebujemy możemy w Prepie dokonać ich agregacji. Przykładowo mając dane dotyczące zamówień rozbitych na poszczególne pozycje (produkty), możemy je zagregować na poziomie zamówienia, aby móc je później analizować. Agregację danych w Prepie tworzymy korzystając z kroku Aggregate (1). W dostępnym edytorze wybieramy grupowane pola, według których odbędzie się agregacja (2) oraz agregowane pola, czyli miary które będą agregowane (3). W naszym przykładzie zrobimy agregację średniej ceny po markach samochodów:
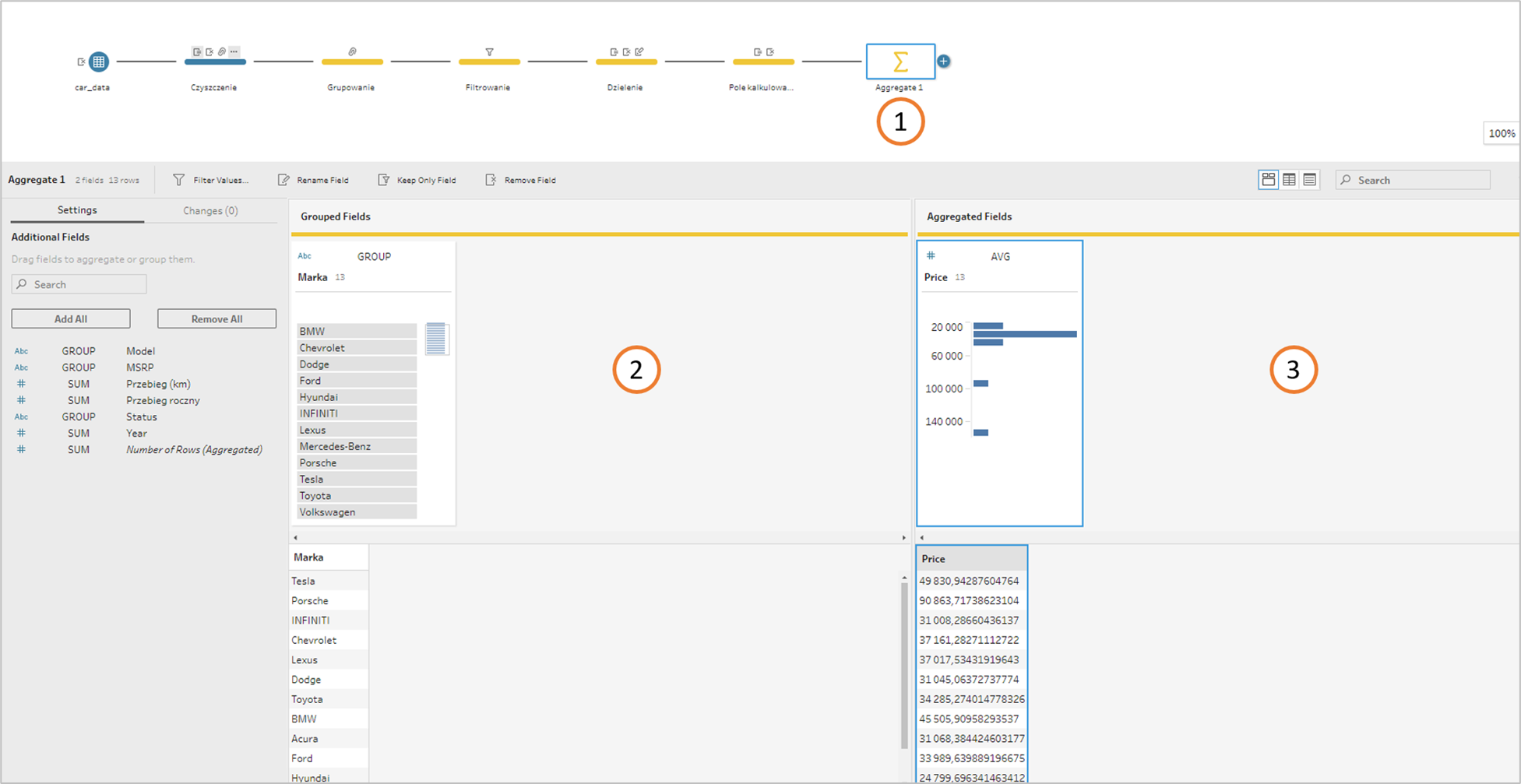
Następnie dodajmy krok Clean aby podejrzeć nasze dane. Jak widzimy – mamy bardzo okrojony dataset składający się jedynie z pól Marka i Cena.
Tutaj zatrzymajmy się na chwilę. Prep umożliwia nie tylko liniowy przepływ danych – możemy tworzyć przepływy równoległe, generując tym samym różne warianty przekształceń tego samego datasetu. Zróbmy to w naszym przypadku, dodając odnogę przed krokiem Aggregate. Uzyskamy tym samym dane szczegółowe w górnej odnodze przepływu, a dane zagregowane w dolnym.

Transpozycja, czyli pivot danych
Często zdarza się w pracy analityka, że dane na których pracujemy nie mają formy bazodanowej, a tabelaryczną. Szczególnie w obszarze finansów, gdzie w wierszach mamy różne miary, a w kolumnach kolejne wartości dla różnych okresów czasu. Aby tak uporządkowane dane analizować w sensownej formie, musimy zrobić ich pivot – czyli po prostu przestawić. Służy temu oddzielny krok Pivot w Prepie. Załóżmy, że chcemy uwzględnić w naszych danych stawki ubezpieczenia, które mamy dostępne w formie tabelarycznej – w wierszach mamy marki pojazdów, a w kolumnach wiek pojazdu:
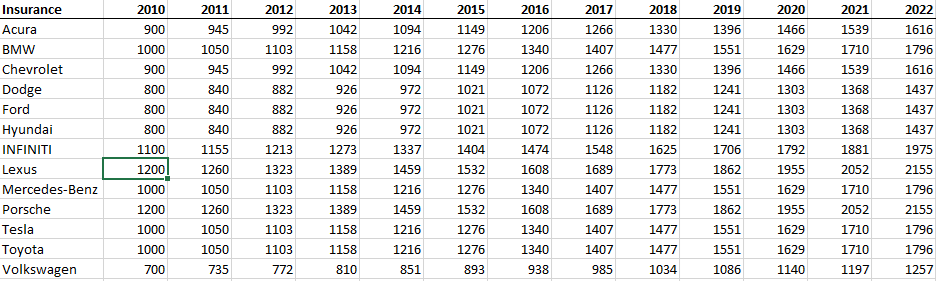
Ładujemy dane do Prepa. Na początek dostajemy dane w takiej samej formie jak w Excelu:
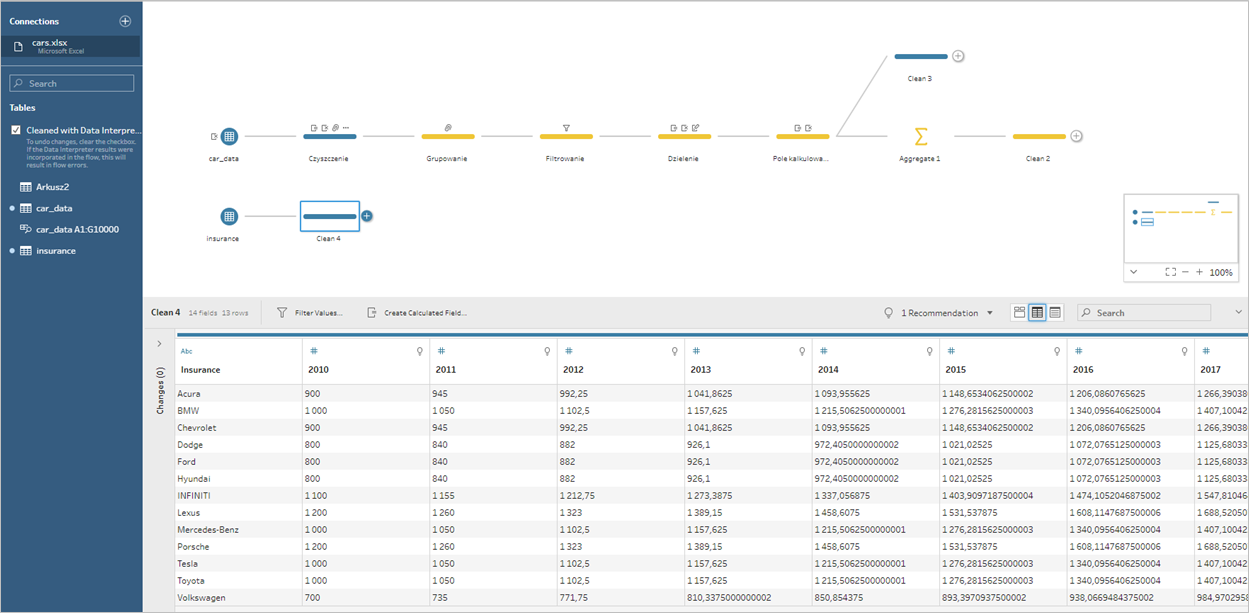
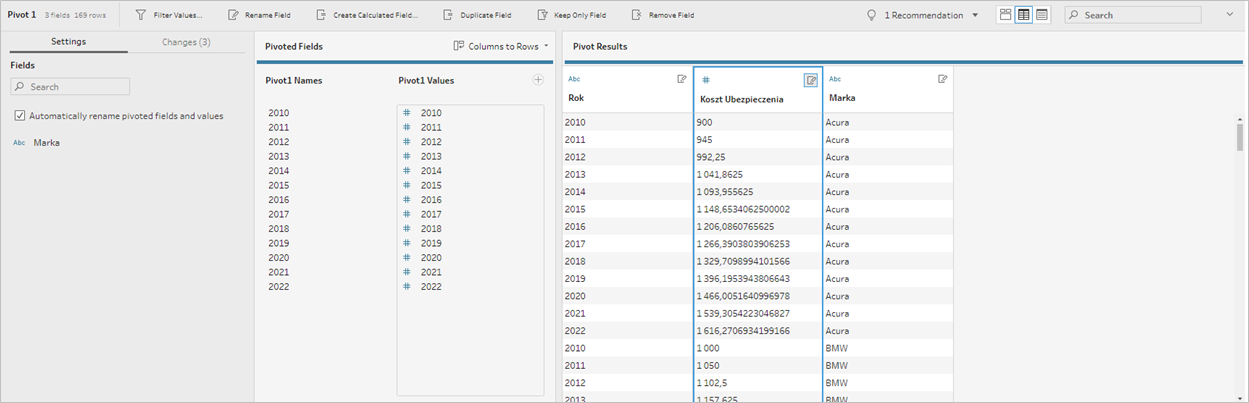
Dodajemy następnie krok Pivot. W edytorze dodajemy nasze kolumny z wartościami jako Pivoted Fields. Zostają one przekształcone w pola z nagłówkami w osobnej kolumnie. Zmieniamy następnie nazwę nowo utworzonych kolumn na Rok i Koszt, a pole Insurance na Marka. Uzyskujemy tym samym bardzo wdzięczną do dalszej analizy formę bazodanową pierwotnej tabeli:
Łączymy dane z wielu źródeł
Jedną z podstawowych operacji w Excelu, które jest niezbędna dla analityka to z pewnością WYSZUKAJ.PIONOWO (VLOOKUP). Jest to o tyle użyteczna funkcja, co potrzebująca dużo mocy obliczeniowej, zwłaszcza na dużych bazach. Pozwala jednak uzupełnić informacje w naszym datasecie z różnych słowników. Można to wykonać w Prepie korzystając z łączenia danych w kroku Join. Wykorzystamy tę funkcjonalność to dodania do naszej bazy kosztów ubezpieczenia. Zacznijmy od dodania nowego kroku Join – który potrzebuje dwóch wejść (input). Jednym będzie nasza baza pojazdów, a drugim tabela kosztów (1):
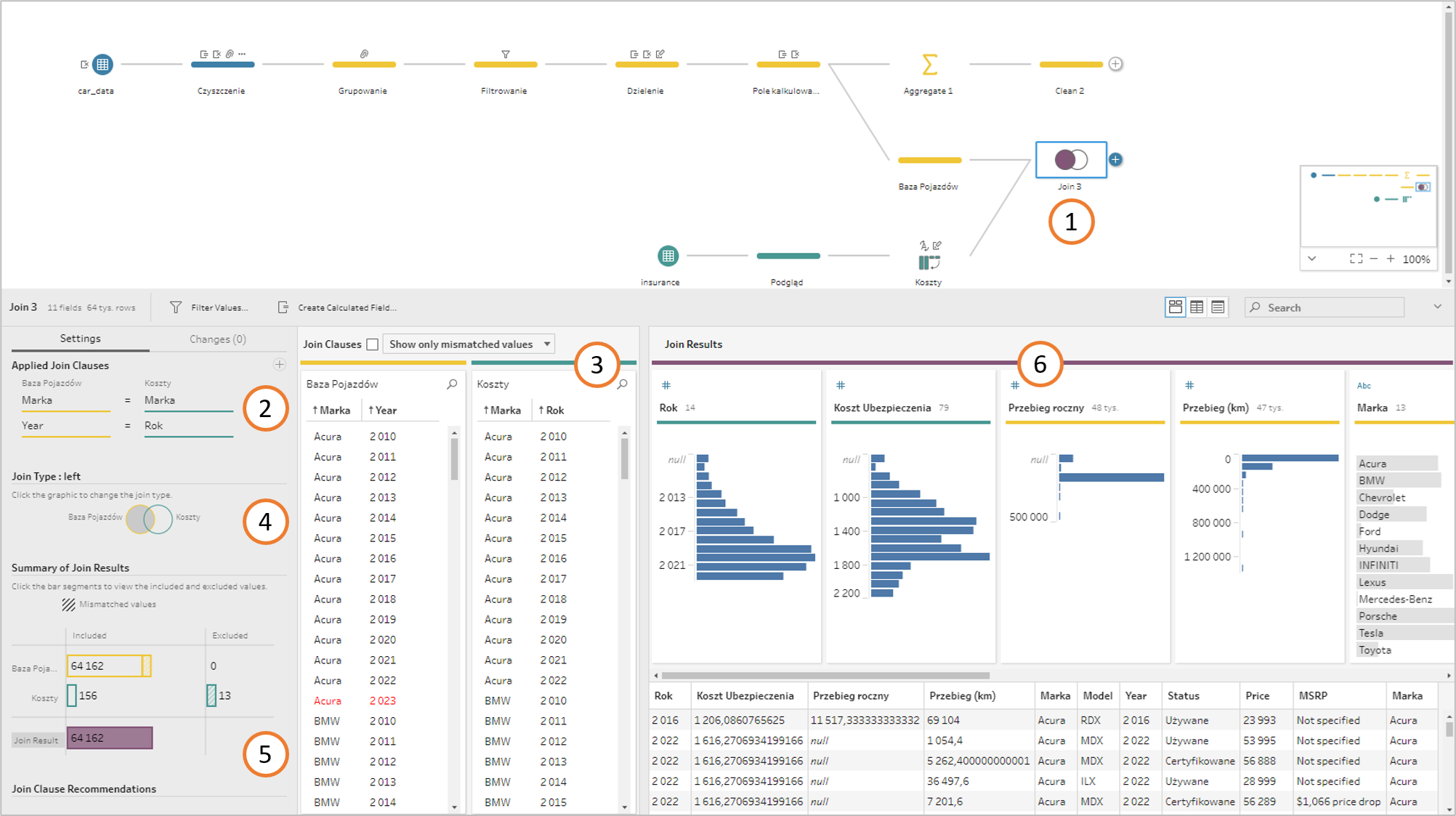
Kolejnym etapem jest definicja Join Clauses – które pola mają być wykorzystane do połączenia. Podgląd widzimy również w oknie (3). Warto również zwrócić uwagę na kolory – wszystko jest zgodne z kolorami w przepływie, co ułatwia rozróżnienie co jest czym. Następnie ustawiamy typ Joina – do wyboru mamy:
1 – left – najbardziej pożyteczny, gdzie do źródła po lewej stronie dokładamy informacje ze źródła po prawej. Jeżeli brakuje jakiegoś przypisania – wyświetli się w okienku (5)
2 – right – analogicznie jak dla left, z tym że do źródła po prawej dokładamy informacje ze źródła po lewej
3 – full – rezultat będzie zawierał wszystkie elementy z lewego i prawego źródła
4 – inner – zwracana będzie część wspólna oraz notInner – zwracane będzie wszystko poza częścią wspólną
5 – left/right only – rezultat zawiera element z jednego źródła, których nie ma w drugim
W praktyce najczęściej używamy left/right. Warto wspomnieć, że wybór rodzaju joina odbywa się również poprzez interfejs graficzny – po prostu wybieramy części, które mają być uwzględnione. Efekt połączonych danych możemy podejrzeć w okienku (6), ponownie zgodnie z kolorystyką we flow.
Innym rodzajem połączenia danych jest Union – w tym przypadku łączymy dane o takim samym układzie, do jednych dokładając drugie. Przykładowo do naszych danych możemy dołożyć dane o sprzedaży z innego regionu albo innej marki. Dodamy najpierw osobne źródło, a następnie w kroku Union połączymy z pierwotną tabelą. Możemy tutaj niejako wpiąć się we flow na wczesnym etapie, aby nie powtarzać transformacji (1).
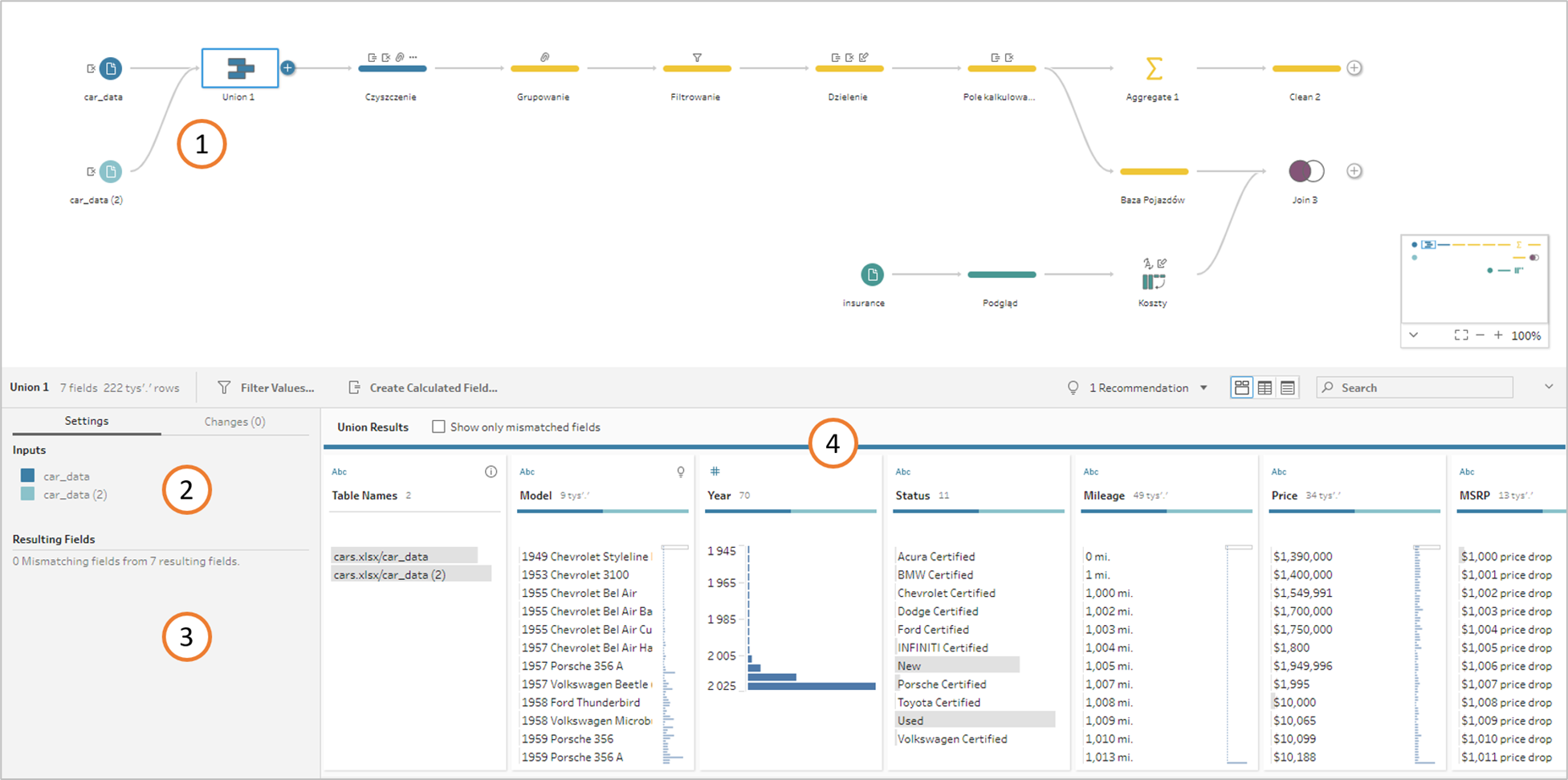
Tabele składowe widzimy w panelu (2), natomiast jeżeli pojawią się jakieś niedopasowane pola (których brakuje w jednej z tabel) to zobaczymy je w panelu (3). Efekt Uniona widzimy w okienku (4), widzimy tam też nowe pole które zostało stworzone automatycznie przez Prepa o nazwie Table Names, wskazujące źródło danych.
Na końcu – eksport danych
Ostatnim krokiem transformacji danych w Prepie jest export do dalszej analizy. Służy temu krok Output, w którym określamy sposób zapisu wyniku (plik, opublikowane źródło danych, baza danych lub CRM). W najprostszym przypadku output będzie plikiem, dla którego musimy określić ścieżkę dostępu (location), rodzaj pliku (extract Tableau, Excel albo plik tekstowy) oraz sposób odświeżenia danych (create – tworzenie tabeli albo Append – dodanie danych do istniejącej tabeli).
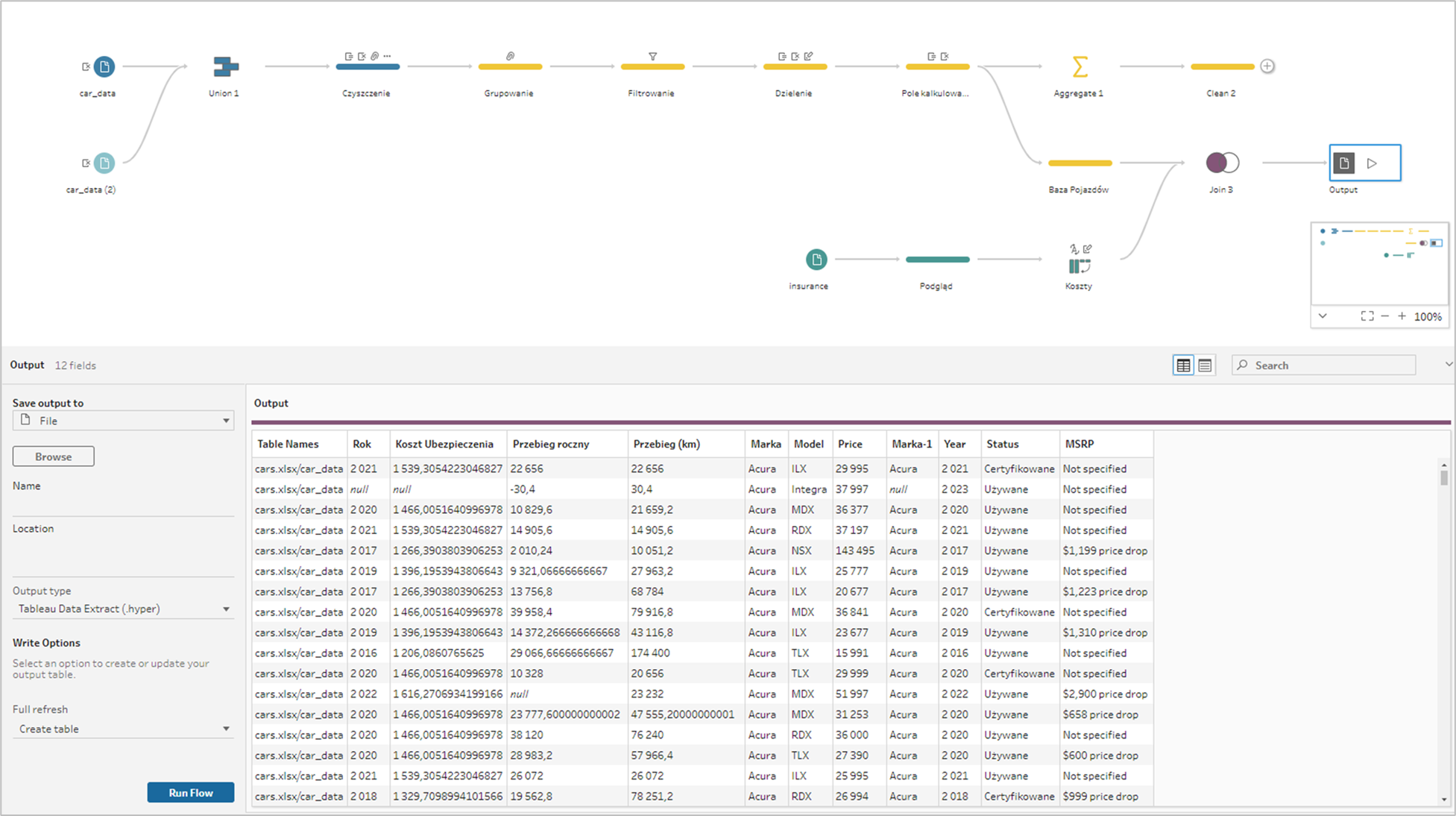
Na samym końcu klikając Run Flow generujemy Output, który następnie możemy wykorzystać przykładowo w Tableau do wizualnej analizy. Jeżeli wszystko poszło ok i Prep nie wykrył żadnych błędów w przepływie danych dostaniemy komunikat:
Tableau Prep w wyposażeniu analityka danych
Prep jest bardzo zgrabnym i nastawionym na aspekt wizualny programem ETL. Nie jest przy tym przeładowany opcjami, a graficzny interfejs ułatwia zrozumienie co dzieje się z naszymi danymi na każdym etapie transformacji. Szczególnie pod kątem późniejszej analizy w Tableau Desktop Prep sprawdza się wyśmienicie, generując od razu extract w formacie hyper. Dzięki temu praca z danymi w Tableau Desktop staje się prostsza i przyjemniejsza dla użytkownika.
Mateusz Karmalski, Tableau Author


