W poprzednim wpisie z serii omówiliśmy wstęp do Tableau Prep. Dowiedzieliśmy się jak zacząć pracę z programem, jak korzystać z interfejsu i jak się po nim poruszać. Zaczęliśmy również transformację danych, poznając krok Clean służący czyszczeniu danych. W poniższym wpisie omówimy kolejne kroki modelowania naszego datasetu, zaczynając od grupowania, poprzez filtrowanie i dzielenie oraz tworzenie kalkulacji. Jak poprzednio kluczem będzie wykorzystanie Prepa jako narzędzia codziennej pracy ułatwiającego transformacje danych.
Grupowanie danych
Grupowanie jest nam potrzebne w wielu sytuacjach, gdy chcemy ograniczyć liczbę występujących elementów w danym polu. Patrząc na nasze dane, wykonamy grupowanie w polu Status – zgrupujemy pola z nazwą marki i słowem Certified w jedną pozycję. Robimy to wybierając opcje danego pola, następnie Group Values i Manual Selection. Na koniec zmieniamy również nazwę grupy na Certified. Dostajemy tym samym ograniczone do trzech opcji pole. Co również istotne – przekształcenie odbywa się na istniejącym polu, a nie jest tworzone nowe. Pozwala nam to utrzymać porządek w danych:
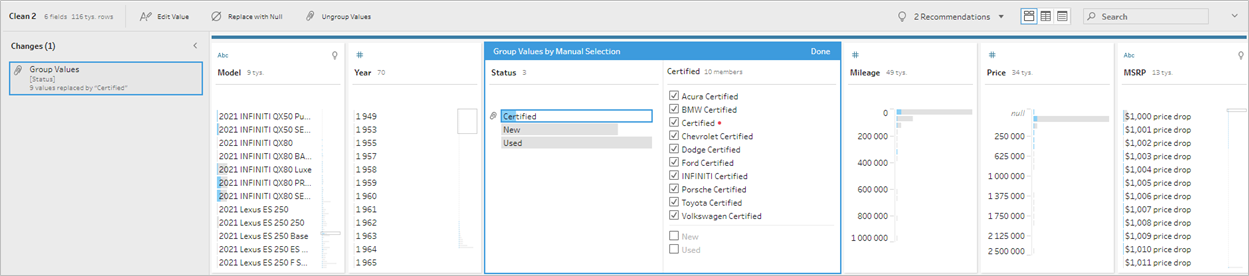
Warto również zwrócić uwagę, że zmiana została odnotowana w polu changes – jeżeli będziemy chcieli ją później edytować bądź usunąć to mamy do niej łatwy dostęp.
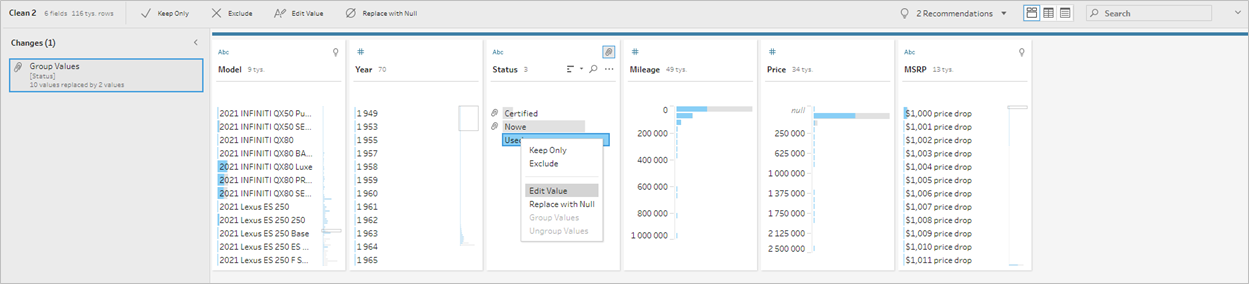
Grupowanie ma jeszcze jedną użyteczną cechę – może być wykorzystywana do zmiany danej wartości. Załóżmy, że chcemy zmienić nazwy z angielskich na polskie. Możemy to zrobić również za pomocą grupowania – klikamy interesującą nas wartość, wybieramy Edit Value i zmieniamy według upodobania. Obok tak edytowanej wartości pojawia się spinacz – graficzny wskaźnik grupowania. Tak naprawdę tworzymy w ten sposób po prostu grupę z jednym elementem, której nazwę możemy edytować:
Filtrowanie danych
Filtrowanie jest jednym z podstawowych działań w transformacji danych, pozwalających wyeliminować to co nas nie interesuje. Dzięki temu pozostają tylko istotne dane, a sam proces analizy staje się prostszy – nie musimy przekopywać się przez nieistotne informacje. W Prepie filtrowanie odbywa w kroku Clean. Filtrowanie w najprostszy sposób odbywa się poprzez wybór opcji danego pola, a następnie pola Filter – mamy wybór:
1 – Calculation – sami tworzymy kalkulację służącą do filtrowania
2 – Selected Values – wybieramy z listy element, które chcemy zachować albo usunąć
3 – null values – do wybory usunięcie nulli albo ich zachowanie
4 – kolejna opcja jest różna w zależności od typu danych: przykładowo dla tekstowych mamy Wildcard Match, gdzie możemy filtrować tekst w zależności od tego czy zawiera dany ciąg znaków, zaczyna się od niego lub kończy. Dla danych liczbowych mamy tutaj Range of Values
Wracając do naszych danych – wykonamy następujące filtrowania: rok powyżej 2010 oraz status tylko Używane albo Certyfikowane. Rok jest liczbą, więc możemy wybrać Range of Values, następnie opcję Minimum (chcemy auta min. Z 2010 roku):
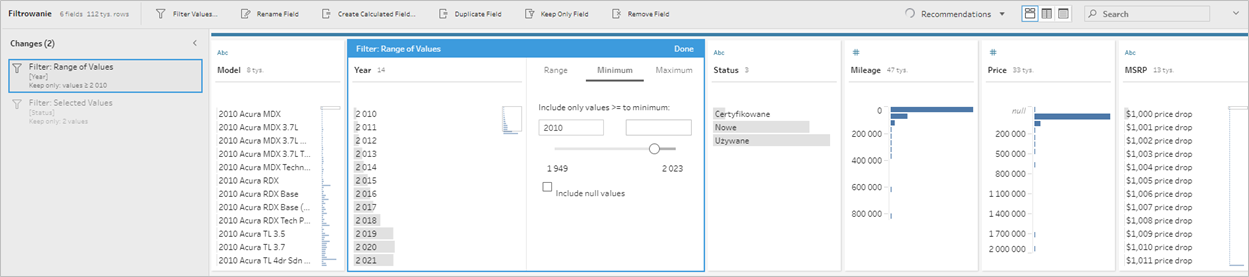
Nasze filtrowanie pojawiło się w panelu zmian po lewej stronie. Kolejne filtrowanie wykonamy na polu Status, gdzie wybierzemy tylko Używane i Certyfikowane – filtrowanie również mamy w liście Changes:

Tak przefiltrowane dane poddamy dalszej obróbce.
Split, czyli wydobywanie informacji z istniejącego pola
Kolejnym przekształceniem, które mamy dostępu z poziomu opcji pola jest Split, czyli dzielenie. Podzielimy pole Model, aby oddzielić rocznik, markę i model. Po kliknięciu opcji pola wybieramy Split, i mamy do wyboru:
1 – automatic split, pozwalając Prepowi samemu rozpoznać klucz według którego ma odbyć się dzielenie
2 – custom split, gdzie sami definiujemy kryteria dzielenia
W prostych przypadkach sprawdzi się automatic, natomiast warto znać custom aby mieć kontrolę nad sposobem dzielenia danych. Wybierając opcję Custom defifniujemy separator (spacja w naszym przypadku) i ile pól ma być zwróconych (np. pierwsze, ostatnie, wszystkie). Ponieważ opisy aut są dość długie i złożone, wyodrębnimy pierwsze trzy elementy: rok, markę i model:

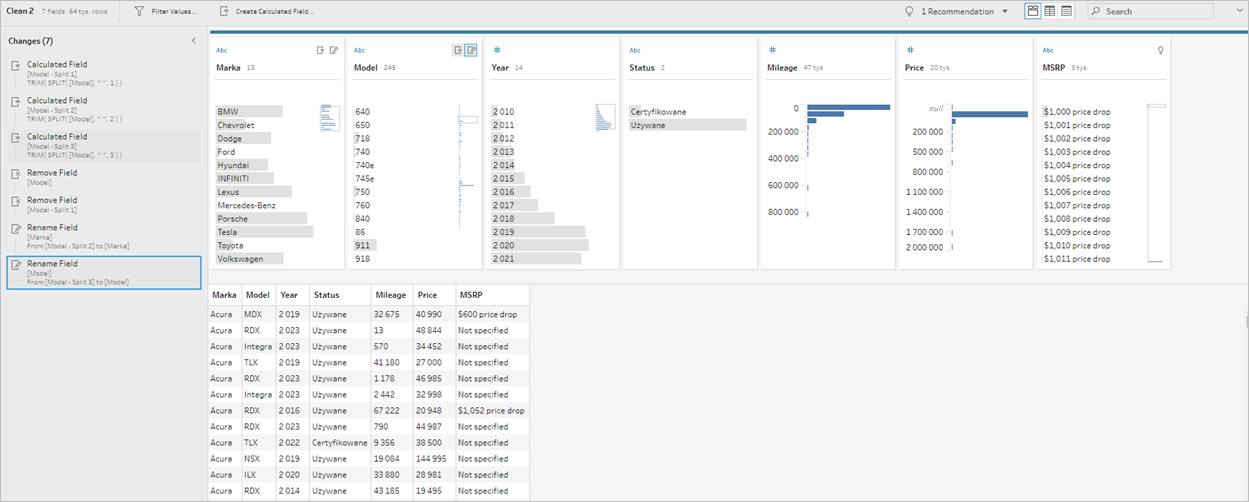
Rocznik mamy co prawda już w naszych danych, ale nie możemy wydobyć w tym momencie środkowych elementów – więc zdublowany rok później usuniemy. Nie będziemy również na tym etapie potrzebowali pola źródłowego Model – usuwamy je wybierając Remove z opcji pola. Ostatnim krokiem będzie zmiana nazw nowo utworzonych pól. Wszystkie zmiany odnotowane są w panelu Changes:
Tworzymy pola kalkulowane
Do tej pory wykorzystywaliśmy przekształcenia z poziomu opcji danego pola, co ułatwiało nam transformacje danych poprzez wykorzystanie interfejsu graficznego. Oprócz tego możemy tworzyć własne kalkulacje, korzystając z szeregu dostępnych funkcji:

Tworzenie kalkulacji odbywa się w analogiczny sposób jak w Tableau. Wykorzystajmy tą opcję do przekształcenia pole Mileage (które jest w milach) w kilometry:

Ponieważ przebieg w dużej mierze zależy od wieku pojazdu, dodamy pole Przebieg roczny. W tym celu musimy najpierw policzyć wiek auta w latach, a następnie podzielić przebieg przez nie:

Oczywiście nic nie stoi na przeszkodzie, aby później tworzyć te kalkulacje w Tableau. Natomiast jeżeli działamy na poziomie pojedynczego wiersza (a nie zagregowanych danych) to warto dokonać tych przekształceń na poziomie przygotowania danych – łatwiej będzie później z nich korzystać w Tableau.
Kolejne kroki za nami
Przypomnijmy – w poprzednim wpisie omówiliśmy podłączenie danych i ich czyszczenie, w tym z kolei przeszliśmy przez grupowanie, filtrowanie, dzielenie (split) oraz tworzenie pól kalkulowanych. Wszystkie te transformacje tworzymy w kroku Clean, natomiast dla przejrzystości możemy je rozbić jako osobne kroki. Dodają do tego koloru i nazwy, zyskujemy doskonały przegląd naszego przepływu danych:

W kolejnym wpisie z serii zajmiemy się agregacją i pivotem danych, łączeniem różnych źródeł (join i union) oraz eksportem danych w celu dalszej – wizualnej analizy w Tableau.
Mateusz Karmalski, Tableau Author


