Wykres liniowy to jeden z podstawowych wykresów wykorzystywanych w wizualizacji danych. Sprawdza się szczególnie w przedstawieniu przebiegów czasowych, gdyż połączenie poszczególnych punktów wskazuje na ciągłość danych. Wykresy liniowe i ich różne warianty odnajdziemy więc na wielu dashboardach i sprawdzą się wszędzie tam, gdzie mamy do czynienia z ujęciem czasowym. Z uwagi na ich wysoką użyteczność, czasem mierzymy się z problem czytelności danych, zwłaszcza gdy mamy dużo przebiegów i chcemy porównywać je między sobą. Prowadzi to do powstania tworu nazwanego „wykresem spaghetti”, z uwagi na niską czytelność i ogólny chaos wizualny przypominający poplątane nitki makaronu. Jest jednak kilka sposób „rozplątania” takiego wykresu.
Budujemy wykres spaghetti
Zanim przejdziemy do rozwiązań, musimy stworzyć sam wykres aby zrozumieć jakie stwarza problemy. Zacznijmy od prostego przebiegu wartości sprzedaży w czasie:
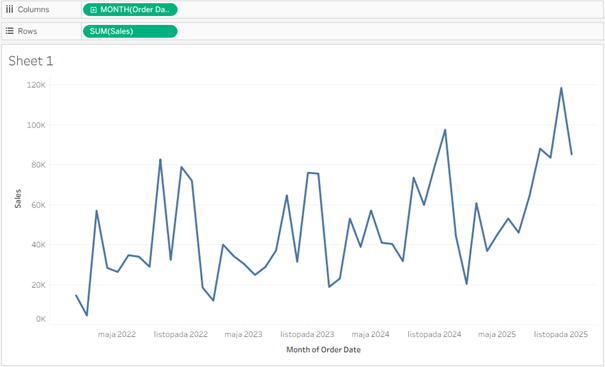
Wykres jest czytelny, przejrzysty, można wyczytać z niego pewne trendy. Dodajmy na początek jeden dodatkowy wymiar z trzema kategoriami:
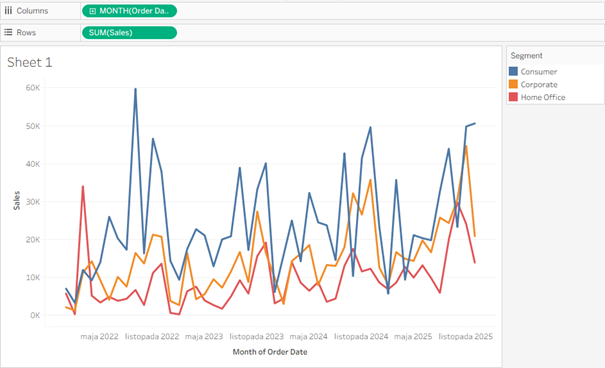
Tutaj już zaczynają się schody – wykresy nakładają się na siebie, czytelność jest już dużo niższa, ale jeszcze nie tragiczna. Dodajmy bardziej szczegółowy widok:
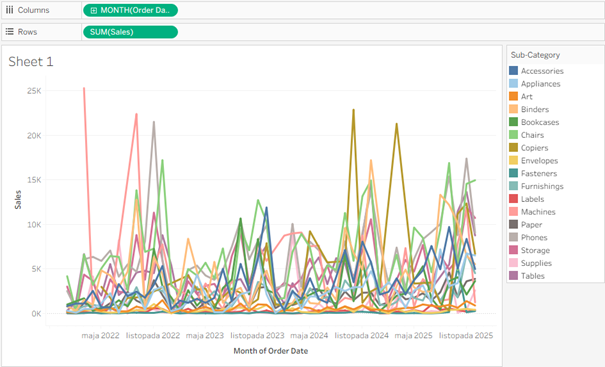
Powyższe już śmiało możemy nazwać wykresem spaghetti – linie nakładają się na siebie, nie sposób ich rozróżnić, zobaczyć jakiekolwiek trendy, porównać między sobą. Wykres w tej postaci jest kompletnie bezużyteczny dla odbiorcy i wymaga nieco pracy, aby można było z niego skorzystać.
Pierwszy sposób – wyróżniamy przebiegi
Pierwszym sposobem radzenia sobie z nadmiarem linii jest wyróżnienie interesującego nas przebiegu. Można to zrobić na kilka sposobów – zacznijmy od filtrowania. Jest to podstawowa metoda interakcji z wykresem i eliminuje nadmiar informacji:
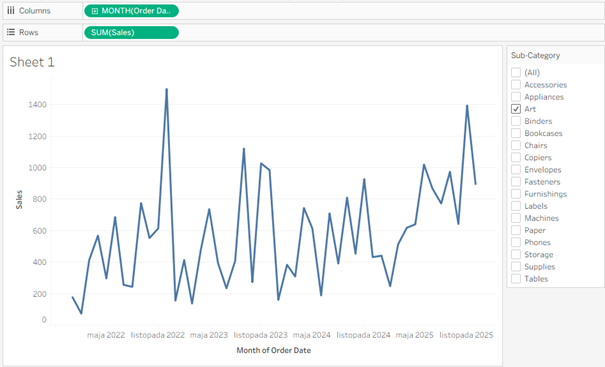
Mamy tu jednak pewną wadę – reszta przebiegów jest całkowicie niewidoczna, nie widzimy jak na ich tle wypada nasza linia. Możemy to obejść wykorzystując highlighter, czyli podświetlenie:
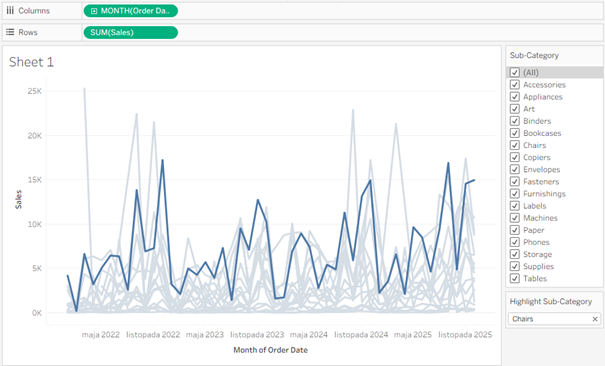
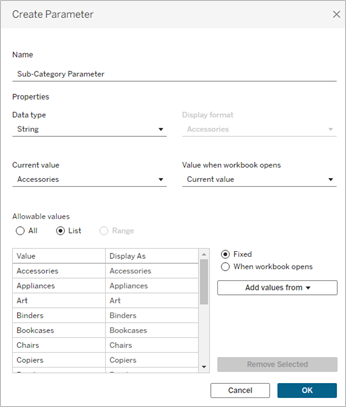
Wygląda to już dużo lepiej – po pierwsze mamy jasno wyróżniony przebieg plus cały pozostały szum zostaje niejako w tle. Highlight ma jednak pewne wady – kliknięcie gdziekolwiek na wykresie resetuje ustawienie oraz nie mamy wpływu na formatowanie wyróżnionej linii. Możemy to obejść wykorzystując parametr – zacznijmy od jego stworzenia na podstawie pola Sub-Category:
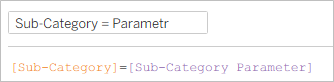
Następnie tworzymy pole obliczeniowe true/false:
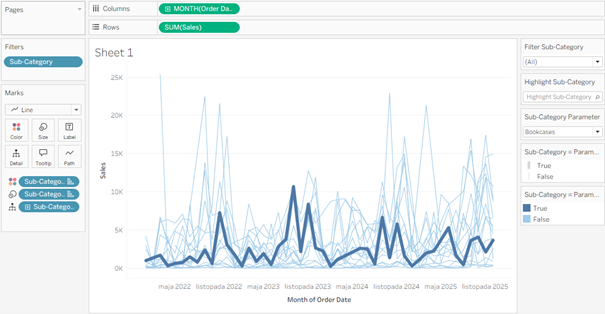
W kolejnym kroku dodajemy powyższe pole obliczeniowe w rozmiar (size) oraz kolor. Mamy tym samym kontrolę nad grubością linii oraz ich kolorem, czego nie mieliśmy w przypadku highlightera . Ustawiamy więc odpowiednią skalę grubości oraz barwy, uzyskując pożądany efekt:
Drugi sposób – oddzielamy przebiegi
Poprzedni sposób jest efektywny, ale wymaga interakcji użytkownika – czy to poprzez filtrowanie czy podświetlanie. Czasem zależy nam bardziej na statycznym ujęciu, przykładowo w celach prezentacyjnych. Pierwszym sposobem ciężko też porównywać przebiegi między sobą – bardziej analizujemy wybrany na tle innych. Jeżeli chodzi nam o inny efekt, to możemy spróbować oddzielić przebiegi. W tym celu z pomocą przychodzą small multiples, czyli małe wielokrotności. Czasem możemy spotkać się też z określeniem wykres panelowy.
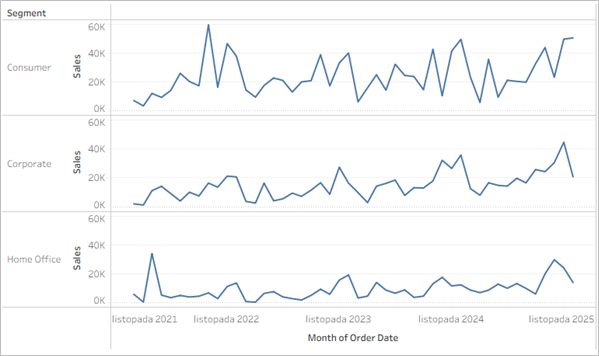
Podstawowym sposobem będzie rozdzielenie przebiegów w wierszach:
Lub w kolumnach:
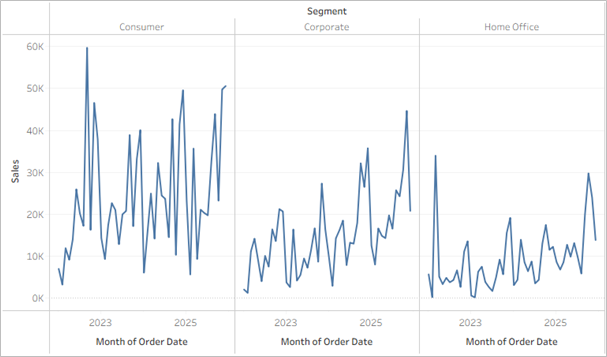
Dzięki takiemu ujęciu rozplątujemy wykres – poszczególne przebiegi są rozdzielone i przez to bardziej czytelne. W przypadku wspólnej osi czasu łatwo jest porównywać przebiegi w tych samych punktach, z kolei na wspólnej osi dla miary łatwiej porównać różnice między kategoriami. Powyższe sprawdzi się jednak dla małej liczby kategorii – jeżeli będzie ich więcej, przebiegi staną się nieczytelne albo będą wymagać suwaka do przesuwania:
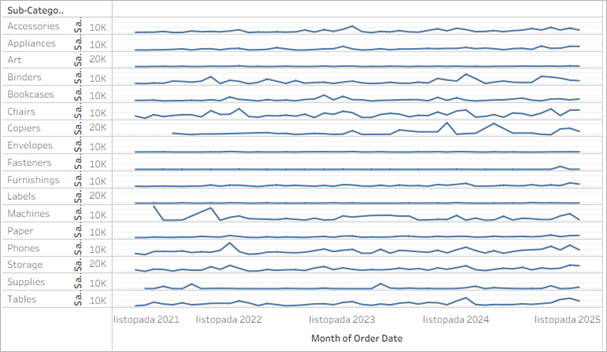
Jak więc poradzić sobie w takiej sytuacji? Najprościej tworząc siatkę wykresów, czyli tzw. grid. Możemy to zrobić na kilka sposobów, najprostszym będzie grupowanie kategorii w wiersze i kolumny. W kolumnach grupujemy po 4 elementy od początku listy, a w wierszach co 4 elementy:
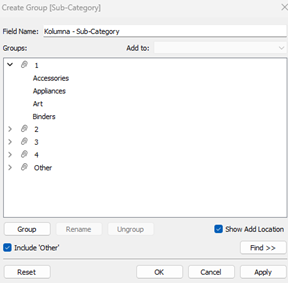
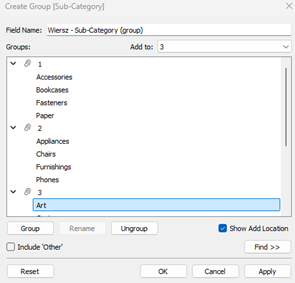
Kolejnym krokiem jest dodanie odpowiednio powyższych pól w kolumny i wiersze, uzyskując tym samym siatkę wykresów:
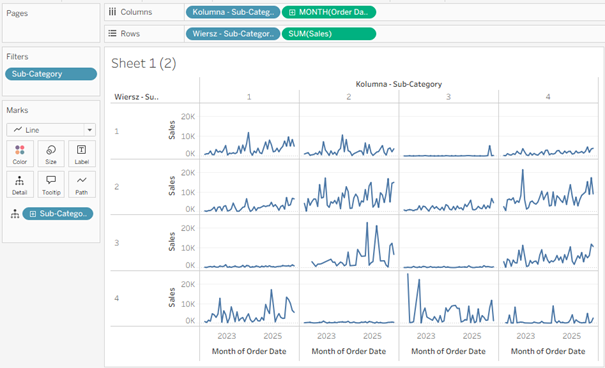
Wykres wymaga nieco formatowania, możemy dodać też etykiety kategorii w postaci dual-axis (tworząc miarę zwracającą max sales aby uzyskać odpowiednie położenie etykiety):
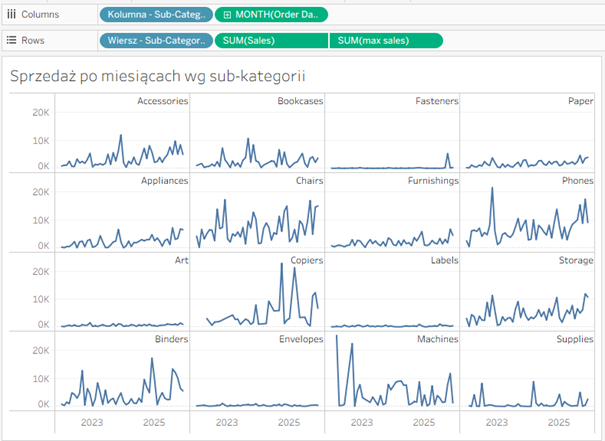
Zyskujemy tym samym rozdzielone przebiegi, do tego łatwe do porównania między sobą – zarówno nominalnie jak i w czasie.
Rozwiązanie zależy od celu
Mierząc się z problemem wykresu spaghetti, najgorszym co możemy zrobić to zostawić go w pierwotnej postaci. Jeżeli zależy nam na szczegółowej analizie konkretnego przebiegu, to lepszym rozwiązaniem będzie sposób pierwszy, czyli wyróżnienie danej linii a usunięcie całej reszty w tło. Wymaga to jednak interakcji ze strony użytkownika – jest to więc bardziej dynamiczny sposób analizy. Jeżeli potrzebujemy statycznego obrazu, to lepszym rozwiązaniem będzie wykres panelowy (małe wielokrotności). Dla małej liczby kategorii możemy wykorzystać pojedynczy wiersz lub kolumnę, a dla większej liczby kategorii – siatkę wykresów (grid).
Mateusz Karmalski Tableau Author


