 Tyle teorii. Z punktu widzenia pracy w Tableau trzeba się zmierzyć z bardziej trywialnym pytaniem: Jak to narysować, mając dane. Wiemy, co mówili ankietowani po przeczytaniu informacji o działaniu pigułek i obejrzeniu opakowania. Dane po wgraniu do Tableau wyglądały tak:
Tyle teorii. Z punktu widzenia pracy w Tableau trzeba się zmierzyć z bardziej trywialnym pytaniem: Jak to narysować, mając dane. Wiemy, co mówili ankietowani po przeczytaniu informacji o działaniu pigułek i obejrzeniu opakowania. Dane po wgraniu do Tableau wyglądały tak:
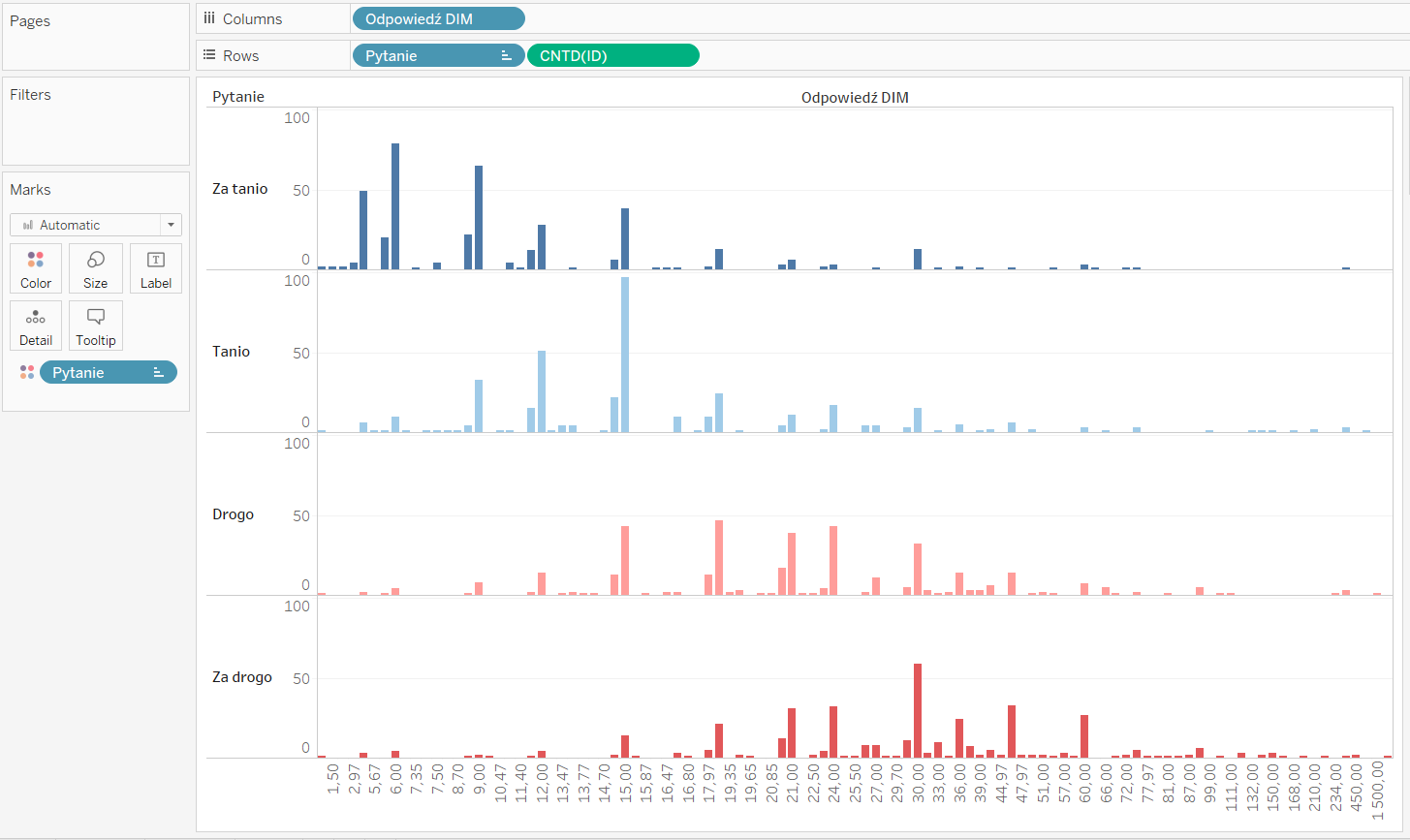
Wstęp – analiza danych i przykładowej wizualizacji
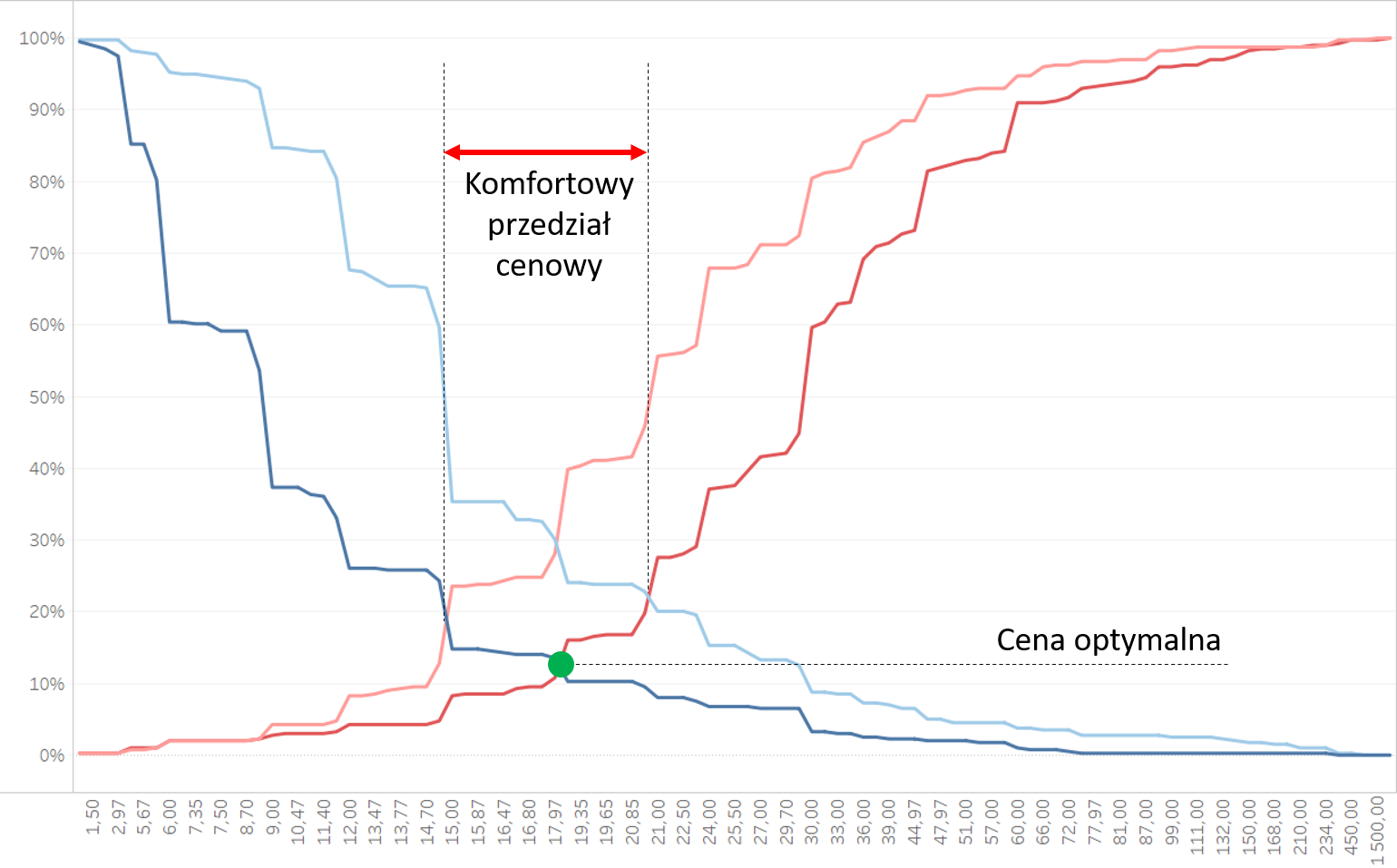
Z pobieżnej analizy przykładowej wizualizacji widać, że na osi X powinny znaleźć się wskazane wartości cen, a na osi Y odsetek respondentów. Kiedy porównamy przykładową wizualizację z rozkładem danych łatwo zorientować się, że w przypadku pozycji „Drogo” i „Za drogo” respondenci zostali policzeni narastająco. Zliczani byli ci, którzy uznali, że „Drogo”, czy „Za drogo” to nie mniej niż dana kwota. Na myśl nasuwa się od razu funkcja RUNNING_SUM lub szybka kalkulacja tabelaryczna RUNNING_TOTAL, a najlepiej od razu przeliczona na procenty. Spróbujmy zatem… I rzeczywiście dla kategorii „Drogi” i „Za drogi” wynik wygląda obiecująco. Gorzej z kategoriami „Tani” i „Za tani”.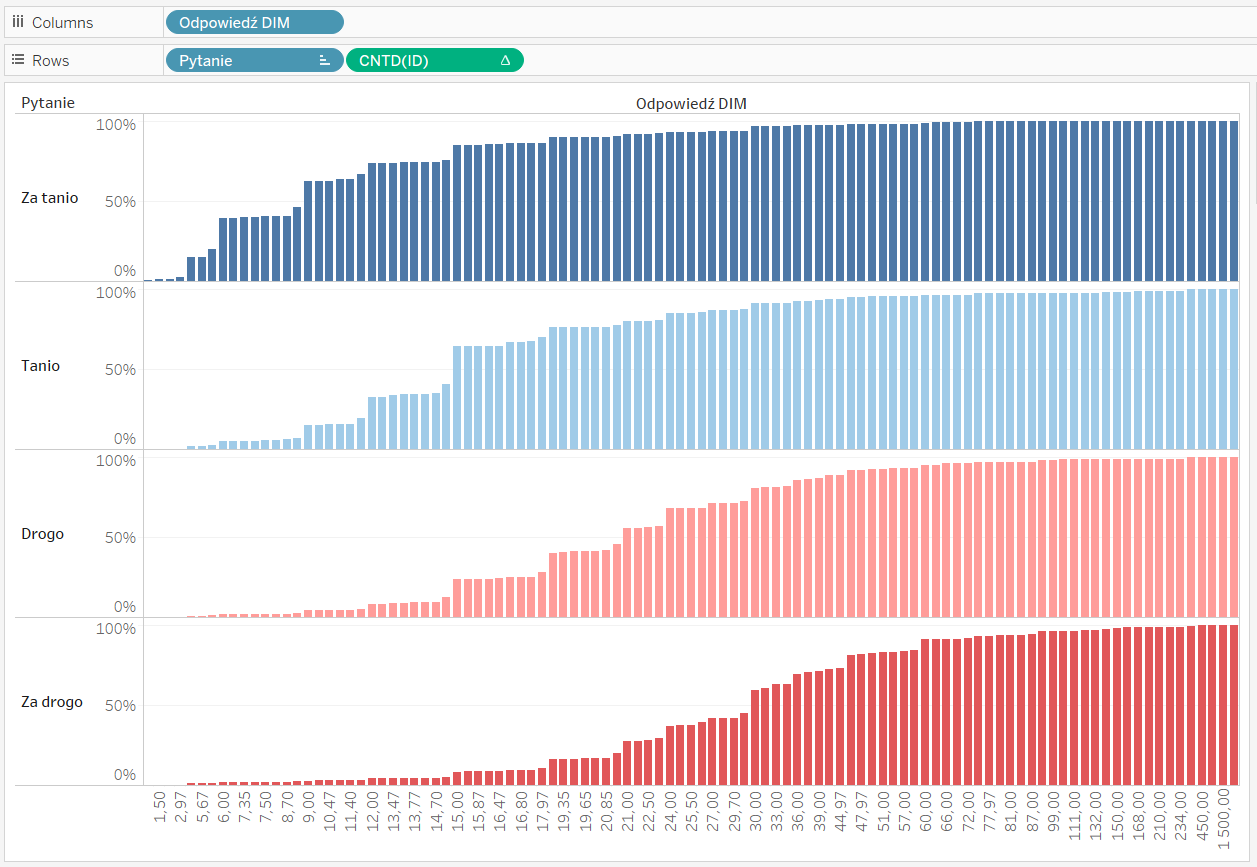
Krok wstecz, czyli interpretacja wizualizacji
I na tym etapie, drogi czytelniku, straciłam dłuższą chwilę. Kiedy trafiłam na obiecującą kalkulację miałam ochotę natychmiast przetestować wszelkie warianty. A tu nic! Jak często bywa w naszej pracy, potrzebne było zatrzymanie się i przeanalizowanie, o co tak naprawdę chodzi. Kiedy wie się „w teorii”, o jaki dokładnie efekt chodzi, przejście do praktyki jest znacznie łatwiejsze. A zatem pozwolę sobie jeszcze raz na analizę pierwszego rysunku. Niebieskie linie rozpoczynają się na 100%, a więc na całkowitej liczbie ankietowanych. Potem odejmowani są wszyscy ci, którzy udzielili konkretnej odpowiedzi. W ten sposób schodzimy do zera przy ostatniej wartości. Jeśli się na to spojrzy z tej strony widać, że kategorie „Tanio” i „Zbyt tanio” zaczynamy zliczać od łącznej sumy ankietowanych, odejmujemy od niej narastającą sumę ankietowanych (RUNNING_SUM() ), a następnie przeliczamy to na procenty. Kiedy tak się to przedstawi, rzecz wydaje się już prosta.Budowa wizualizacji danych
Czas przejść do wykonania. Wiemy już, że powinniśmy stworzyć dwie osobne kalkulacje dla kategorii „niebieskich” i „czerwonych”. Zacznijmy jednak od rozdzielenia tych kategorii. Do tego posłużą nam dwa pola kalkulowane. Co się na nie złoży? Dla ułatwienia: Pole [Pytanie] to lista naszych czterech pytań. ID to identyfikator ankietowanego. Teraz możemy napisać już kalkulacje główne.
Teraz możemy napisać już kalkulacje główne.
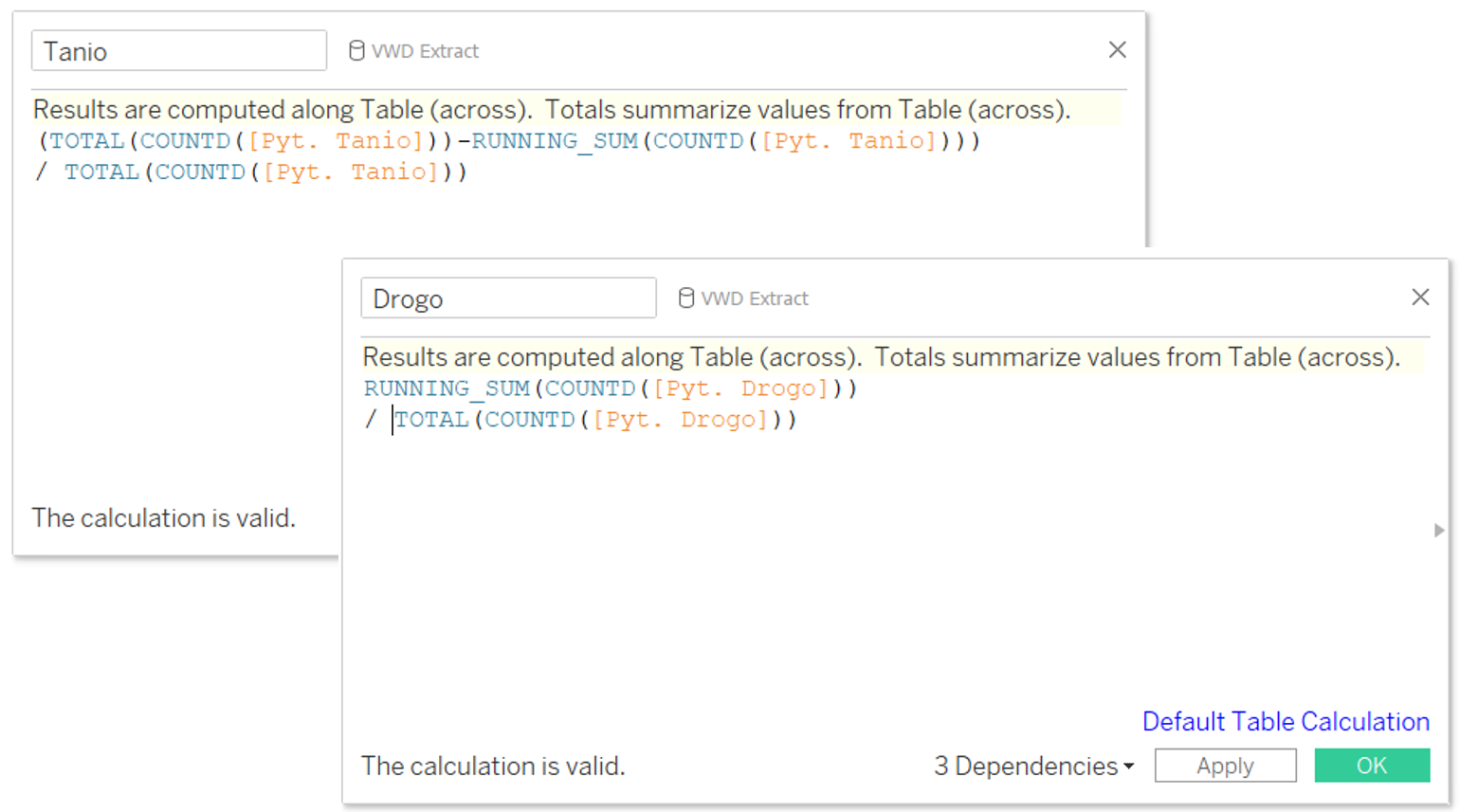 Na koniec umieszczamy kalkulacje [Drogo] i [Tanio] w wierszach, łączymy je opcją Dual Axis, synchronizujemy osie i upewniamy się, że [Pytanie] znalazło się na półce Color. Na szczęście wystarczy tu automatyczny kierunek liczenia kalkulacji tabelarycznych – Table Across. Nie trzeba go zmieniać. Teraz możemy więc już odczytać wyniki. Ankietowani są skłonni zapłacić za nasze magiczne pigułki między 15 PLN a 21 PLN. Cena optymalna to 18 PLN.
Na koniec umieszczamy kalkulacje [Drogo] i [Tanio] w wierszach, łączymy je opcją Dual Axis, synchronizujemy osie i upewniamy się, że [Pytanie] znalazło się na półce Color. Na szczęście wystarczy tu automatyczny kierunek liczenia kalkulacji tabelarycznych – Table Across. Nie trzeba go zmieniać. Teraz możemy więc już odczytać wyniki. Ankietowani są skłonni zapłacić za nasze magiczne pigułki między 15 PLN a 21 PLN. Cena optymalna to 18 PLN.
 Sięgnęłam po ten przykład, bo Tableau to program, za którym stoi fantastyczna społeczność. I bardzo rzadko zdarza się temat taki jak ten – niemal zupełnie nie opisany. Na szczęście Tableau daje mnóstwo elastyczności do tworzenia wizualizacji ad hoc. Najważniejsze, by dokładnie wyobrazić sobie efekt, który chcemy uzyskać i nazwać go. Najciekawsze zadania w pracy konsultanta to te, gdy klient mówi „Chciałbym, żeby to działało tak…” albo „Potrzebuję rozwiązania, które pozwoli…”. Sposób znajdziemy niemal zawsze.
Agata Mężyńska,
Tableau Desktop Certified Professional
Sięgnęłam po ten przykład, bo Tableau to program, za którym stoi fantastyczna społeczność. I bardzo rzadko zdarza się temat taki jak ten – niemal zupełnie nie opisany. Na szczęście Tableau daje mnóstwo elastyczności do tworzenia wizualizacji ad hoc. Najważniejsze, by dokładnie wyobrazić sobie efekt, który chcemy uzyskać i nazwać go. Najciekawsze zadania w pracy konsultanta to te, gdy klient mówi „Chciałbym, żeby to działało tak…” albo „Potrzebuję rozwiązania, które pozwoli…”. Sposób znajdziemy niemal zawsze.
Agata Mężyńska,
Tableau Desktop Certified Professional

