Wdrożenia narzędzi BI- problem 1. Brak danych
Najgorzej jest oczywiście wtedy, gdy danych po prostu nie ma. Wtedy zostaje nam albo pogodzenie się z tym stanem rzeczy, albo stworzenie jakiegoś obejścia. Rodzaj zastępczej ewidencji, która przynajmniej częściowo taką lukę uzupełni. Trzeba tu jednak bardzo uważać, aby nie wpaść w pułapkę „Excelozy”. Chodzi tutaj o zjawisko, w którym firma obrasta setkami arkuszy Excela, pełniących de facto rolę pomocniczych baz danych. (Ostatnio w jednym z zapytań ofertowych pojawiło się zagadnienie „Zapewnienia bezpieczeństwa nieformalnych źródeł danych”…).
„Exceloza” jest o tyle groźna, że często owe „pomocnicze” arkusze stają się de facto źródłami absolutnie krytycznych dla funkcjonowania Firmy informacji – w praktyce niezabezpieczonymi w jakikolwiek sposób. Wiele razy widziałem takie pliki z rejestrami np. podpisanych umów, terminami wygaśnięcia kontraktów serwisowych, warunkami gwarancyjnymi dla poszczególnych Klientów, czy kolejnymi wersjami cenników produktów, leżały sobie spokojnie na ogólnodostępnym dysku, niezabezpieczone przed utratą, skopiowaniem, czy nieautoryzowanym dostępem…
Żeby było jasne – nie ma nic złego we WPISYWANIU danych przy pomocy EXCELA. Jest to nawet bardzo wygodne narzędzie do tego celu. Groźne może być na dłuższą metę PRZECHOWYWANIE danych w tym narzędziu. Plik można utracić znacznie łatwiej niż serwerowe repozytorium bazy danych …
Zatem zalecane przez nas rozwiązanie problemu braku pomocniczych ewidencji, to tworzenie ich tak, aby dane trafiały do bezpiecznej bazy danych. Narzędziem do ich wprowadzenia może być oczywiście nasz poczciwy EXCEL, przeglądarka www, czy jakakolwiek inna postać formularza. Dane będą bezpieczniejsze, a ich wykorzystanie w narzędziach BI znacznie łatwiejsze, stabilniejsze i dające się zautomatyzować.
Problem 2. Scalenie i nałożenie na siebie danych z różnych systemów (różne obszary merytoryczne)
To się zdarza bardzo często – potrzebujemy skonfrontować ze sobą dane o sprzedaży i płatnościach, sprzedaży i reklamacjach, zamówieniach i stanach magazynowych, sprzedaży i liczbie wizyt u danego Klienta, zamówieniach i produkcji itp. Często „u źródła” występują one w różnych bazach danych, różnych formatach. Nawet gdy wszystko dzieje się w obrębie jednego zintegrowanego pakietu, bardzo często ta sama kolumna w różnych tabelach nosi różne nazwy itp. Większość współczesnych narzędzi BI ma możliwość łączenia danych z różnych źródeł. Jest to łatwiejsze, lub trudniejsze – dość ciekawie rozwiązano rzecz w Tableau. Jest tam wbudowanych ok. 80 sterowników do różnych źródeł danych, ale co ciekawe, w jednym tzw. ekstrakcie danych możemy nakładać na siebie tabele pochodzące z różnych źródeł. Wówczas nasz model danych może wyglądać na przykład tak:
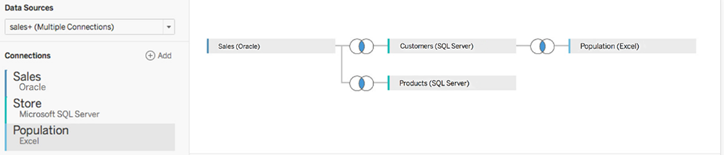 Jak widzimy, w jednej analizie nakładamy na siebie tabele z danymi sprzedażowymi z bazy Oracle, danymi o Klientach i produktach z MS SQL SERVER i pomocnicze dane demograficzne z … arkusza EXCELA. Tabele możemy łączyć różnymi relacjami. Czyli definiować, która tabela „filtruje” którą – czy „Lewa Prawą”, czy „Prawa Lewą”, czy bierzemy część wspólną z obu, czy bierzemy pełen zakres obu tabel – wtedy mamy odpowiednio „Left Join”, „Right Join”, „Inner Join” lub „Full Outer Join”. W zależności od typu relacji mamy pełny lub ograniczony zakres danych, niepowiązane rekordy wyświetlają się jako „nulle”, albo wcale ich nie widać itp. Wymaga to oczywiście pewnej wprawy i znajomości logiki danych. To jest ten etap wdrożenia, na którym można „zrobić sobie krzywdę” i zdefiniować np. model oparty na iloczynie kartezjańskim. W takim modelu wszystko wiążemy ze wszystkim i możemy wygenerować jakąś gigantyczną i nie mającą sensu liczbę rekordów w tabeli wynikowej. Trzeba zatem wiązać tabele według tych kolumn, dla których ma to sens (np. „NIP” pomiędzy tabelą „Kontrahenci” a tabelą „Faktury”)
Jak widzimy, w jednej analizie nakładamy na siebie tabele z danymi sprzedażowymi z bazy Oracle, danymi o Klientach i produktach z MS SQL SERVER i pomocnicze dane demograficzne z … arkusza EXCELA. Tabele możemy łączyć różnymi relacjami. Czyli definiować, która tabela „filtruje” którą – czy „Lewa Prawą”, czy „Prawa Lewą”, czy bierzemy część wspólną z obu, czy bierzemy pełen zakres obu tabel – wtedy mamy odpowiednio „Left Join”, „Right Join”, „Inner Join” lub „Full Outer Join”. W zależności od typu relacji mamy pełny lub ograniczony zakres danych, niepowiązane rekordy wyświetlają się jako „nulle”, albo wcale ich nie widać itp. Wymaga to oczywiście pewnej wprawy i znajomości logiki danych. To jest ten etap wdrożenia, na którym można „zrobić sobie krzywdę” i zdefiniować np. model oparty na iloczynie kartezjańskim. W takim modelu wszystko wiążemy ze wszystkim i możemy wygenerować jakąś gigantyczną i nie mającą sensu liczbę rekordów w tabeli wynikowej. Trzeba zatem wiązać tabele według tych kolumn, dla których ma to sens (np. „NIP” pomiędzy tabelą „Kontrahenci” a tabelą „Faktury”)
Wdrożenia Business Intelligence – Problem 3. Scalenie danych bieżących z archiwalnymi (np. przy zmianie systemu informatycznego)
Rzecz występuje bardzo często. Nasz poprzedni system pracował z bazą danych np. Progress, albo MS SQL, a „przesiedliśmy się” na Oracle, albo MySQL. A potrzebujemy wieloletnich analiz np. trendów sprzedażowych, czy historii płatności danego Kontrahenta. Co wtedy?
Aby uniknąć żmudnego „dziobania” w starym i nowym narzędziu oraz niebagatelnych kosztów migracji pełnej bazy danych ze starego do nowego systemu. Zwykle w takiej sytuacji przenosimy jakieś wielkości graniczne – np. tylko „Bilans Otwarcia”, ewentualnie tylko nierozliczone pozycje na dzień uruchomienia nowego systemu. Najlepiej jest „zrzucić” dane z obu systemów do zewnętrznego narzędzia Business Intelligence. Oczywiście, w przypadku „starego” systemu, będzie to działanie jednorazowe, tworzące „Archiwum danych”. W przypadku „nowego” zwykle jest to powiązane z normalnym wdrożeniem narzędzia BI. Aby jednak te dane „widziały się” ze sobą, nie wystarczy że będziemy je mieli w dwóch „sąsiednich” kostkach OLAP, czy tabelach. Tutaj bardzo przydatna jest funkcja „Append to Datasource”, występująca w niektórych narzędziach BI. Daje ona możliwość (po uprzednim „zmapowaniu” części wspólnej obu źródeł danych, czyli wyznaczeniu odpowiadających sobie kolumn w obu źródłach danych) „doklejenia” rekordów z jednego źródła danych do kolejnego. W taki sposób jakbyśmy po prostu dokleili kolejne wiersze w tabeli. W efekcie uzyskujemy JEDNO źródło danych zarówno dla danych ze starego systemu, jak też nowego – i to z tą samą granulacją danych!
Warto zwrócić uwagę coś takiego, jak „unia danych”. Gdy źródłami danych są np. identyczne pliki CSV dla różnych zakresów czasowych, krajów, czy produktów, można je bardzo łatwo połączyć w „Unię”. Dzięki czemu będą one rozpoznawane jako jedno źródło danych. Warto zapytać o takie funkcjonalności dostawcę naszego narzędzia BI, zarówno „Append to Datasource”, jak też „Data Union” mogą być kapitalnie pomocne w scaleniu danych z różnych systemów.
Wdrożenia BI – Już wkrótce zapraszamy do przeczytania kolejnej części artykułu.


