Deduplikacja danych (jeden kontrahent w pięciu postaciach, literówki itp.).
To jeden z najczęściej występujących problemów. Można (i należy!) go rozwiązać na kilku etapach:
1. U źródła – czyli na etapie ewidencji, wdrażając rozmaite procedury weryfikujące, listy/ raporty kontrolne, wyłapując i weryfikując kontrahentów o tym samym NIPie, adresie, podciągu znaków w nazwie itp.)
2. Na etapie ETL, czyli zasilania danymi narzędzia BI – takie procedury deduplikacyjne są standardowym rodzajem skryptów ETL.
3. W samym narzędziu BI – tutaj zwykle mamy do dyspozycji kilka narzędzi.
Zawsze warto zdefiniować kilka analiz „weryfikacyjnych”, wyłapujących np. zdublowane rekordy w bazie danych – większość współczesnych narzędzi BI ma możliwość już na etapie analizy danych wykonywania operacji typu „Hide”, „Group”, „Exclude”, „Rename”. Można to zrobić w bardzo prosty sposób nawet na etapie wizualizacji danych – wyłapując np. elementy wybitnie odstające:
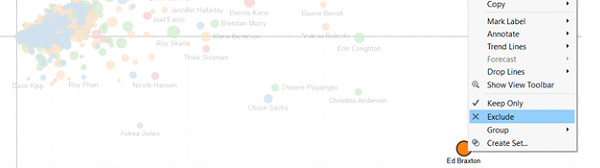
Tutaj bardzo przydatna może być opcja „View Data”, czyli podglądu danych szczegółowych dla danego obiektu:
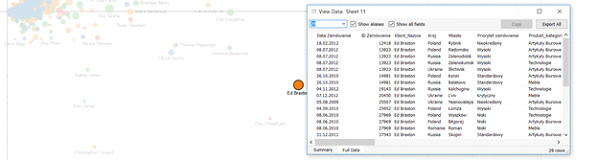
Dzięki temu możemy błyskawicznie wyłapać zduplikowane obiekty.
Kolejna rzecz – warto sprawdzić, czy nasze narzędzie BI daje możliwość wyłapania różnego typu „niezmapowanych” obiektów. Może się to odbywać przy pomocy np. komunikatu „Unknown”, jak w przykładzie poniżej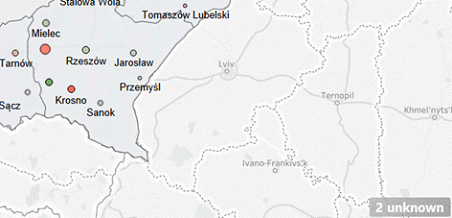
Mamy tu fragment analizy na mapie ze znacznikiem pokazującym, że są tu 2 rekordy o statusie „unknown” – czyli „nieznane systemowi”. Klikając na ów szary prostokąt możemy zobaczyć przyczynę (w pole „Miasto” wpisano Województwo) oraz rozwiązać problem wpisując poprawne mapowanie:
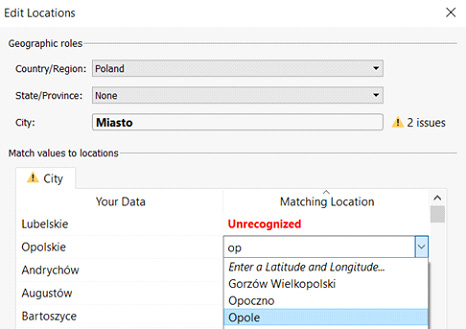
Co istotne, nie wstrzymuje to procesów ETL, to Użytkownik decyduje, czy chce takim danym zaufać, czy nie. To również bardzo ważna rzecz – mieliśmy w przeszłości wiele razy do czynienia z sytuacją, gdy odświeżenie Hurtowni Danych potrafiło zatrzymać się z powodu jakiegoś drobnego błędu w danych, powodując spore zakłócenia w funkcjonowaniu Firmy…
Mapowanie danych (np. wyciągnięcie wymiarów z konta księgowego, grupowanie produktów)
To zagadnienie ma kilka aspektów. Pierwszy – to oczywiście możliwość zdefiniowania nowych wymiarów/ przekrojów analitycznych na podstawie innych wymiarów (np. podciągu znaków konta czy indeksu). Warto zweryfikować możliwość skorzystania w naszym narzędziu BI z tzw. Splittera, który może jednym kliknięciem przekształcić np. wymiar „Imię i Nazwisko” w dwa osobne wymiary „Imię” i „Nazwisko” jak na przykładzie poniżej:
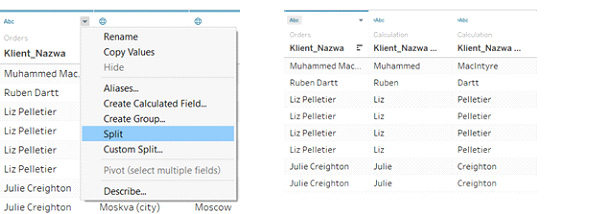
(nie mniej ciekawy jest tzw. „Custom Split”, dający możliwość wyznaczenia, jak dane mają być rozdzielone i w oparciu o jakie znaki 🙂
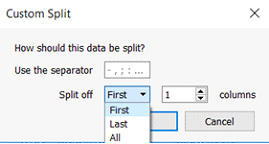
Oczywiście, niezależnie od tego, co możemy zrobić „jednym kliknięciem”, pozostają nam również znane z Excela, a stosowane w różnych narzędziach funkcje rozdzielania tekstu typu „Left”, czy „Right”. Bardzo przydają się one w sytuacjach, gdy chcemy np. „wyłuskać” 5 i 6 znak z indeksu i stworzyć z nich oddzielny wymiar.
Ale nie mniej ciekawe jest tworzenie nowych wymiarów na podstawie poziomu miar – np. klasyfikacji ABC Klientów, czy produktów. Kiedyś było to dość skomplikowane, dziś wystarczy napisać dość prosty warunek, np:
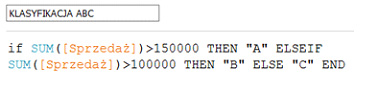
I nasz nowy wymiar jest gotowy do użycia:
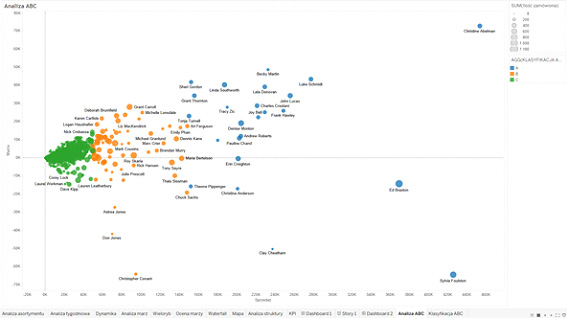
Równie częstym zjawiskiem jest problem tzw. „długich ogonów”, czyli wielkości o marginalnym znaczeniu, które zaciemniają nam całą analizę. Może to powodować efekty takie jak poniżej. Jak widzimy, połowa obszaru analizy poświęcona jest danym o zupełnie marginalnym znaczeniu. Jeśli mamy możliwość zgrupowaniu ich na ekranie np. w ten sposób:
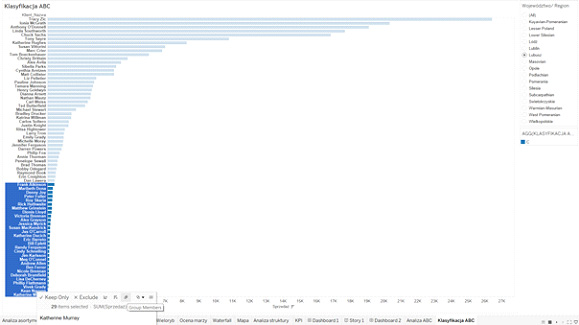
I oznaczenia aliasem „Pozostałe”, to nasza analiza sporo zyskuje na czytelności – a zostaje jeszcze miejsce na inne ciekawe elementy analizy, jak trend, czy KPI:
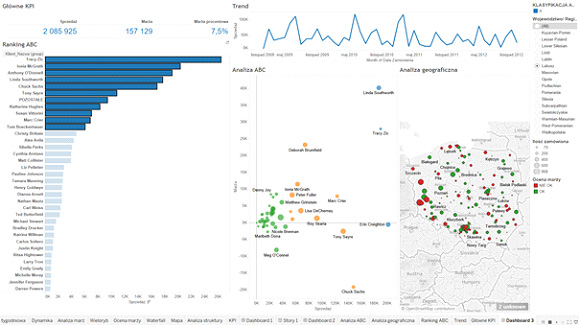
Oczywiście, to dopiero początek listy, kolejne ciekawe aspekty modelowania danych i dopasowywania ich do naszych potrzeb opiszę w kolejnym artykule – zapraszam serdecznie!
Witold Kilijański, Prezes Zarządu
NewDataLabs sp. z o.o.


