– or how to simplify the analysis of huge amounts of data for thousands of users without compromising on cost, speed and security
Access to data has changed the way many businesses are run. This has been influenced by data, which has become the source of information needed to make decisions. Getting access to the right data is now a priority for many organizations. In contrast, the data infrastructure is often not adapted to the requirements of users from different departments of the company. People who manage data often can’t meet all user demands without the right tools to make relevant data available to specific user groups. See how Snowflake makes working with data easier.
Snowflake data warehousing, and user access in your company
The data that is collected in data warehouses can come from many different sources. These are usually systems used in various departments of a company, e.g. ERP (warehouse), CRM (sales) or PLM systems, i.e. systems related to product life cycle. Data also flows in from equipment on production lines, the Internet, marketing systems, and even social media channels. In order to prepare the data for further analysis, it needs to be placed in a single warehouse. In this way, different business units can examine and analyze information from multiple angles, pulling data from one place. However, for this concept to work properly, it requires a special mechanism to disseminate the data to different audiences. Executives most often require specific data already summarized, ready to be analyzed for business decisions. Analysts, on the other hand, want raw data so that existing relationships, information and conclusions can be found. Managers need the data already filtered so that they can track the performance of their teams, comparing it in with the data in looking at the organization as a whole. If one system is to serve all audiences then it needs to be scalable to provide access to data for all audiences.
Snowflake – from the data controller’s point of view
In Snowflake, data is loaded from various sources, stored, and available to users at any time to answer any number of data queries. Those who manage data no longer need to focus on creating structures to deal with data access contention issues. They can store all their data in one system and provide access without having to think about how different user groups might affect access and data resource consumption. This way, you can load the data and set up multiple groups for simultaneous access. Additionally, they have the ability to make their own queries to the data with almost unlimited dedicated computing resources. This means no more waiting for other groups to release resources. Your company can now deliver analytics to a variety of users: executives, analysts, data analysts, and managers, without influencing each other to achieve high performance.
Snowflake data warehouse – data architecture
Snowflake and its unique architecture allows almost instant access to a virtually unlimited number of computing resources. Running multiple data workloads at the same time using more than one virtual storage has no impact on performance.
Examples of data loads:
- Ad hoc analysis: analysis or ad hoc queries e.g. performed in Tableau
- Data loading: COPY command that continuously loads data from an external data source
- Data transformations: A series of commands to transform raw data into a more useful format
- Reporting: Dashboards and other reports refreshed on schedule or on demand by executives
- Reading data by users: End-user applications that display data -Transformation of data: A huge data batch transformation that is run and refreshed very frequently.
Each ETL data operation may have its own separate resources, even when each operates on the same databases and tables.
The Snowflake data warehouse provides the required resources, such as CPU, memory, and temporary storage, to execute SELECT, UPDATE, DELETE, and INSERT commands.
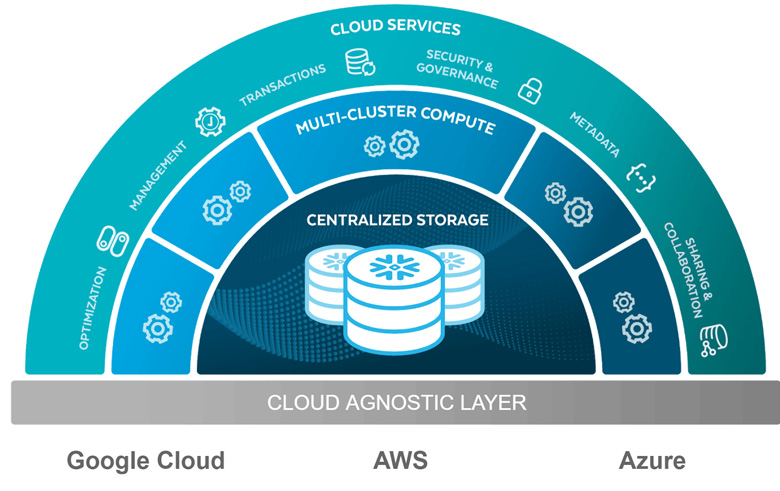
When we talk about Snowflake’s multitenant compute layer we are referring to a virtual data store that executes queries on a centralized layer. Below is an architectural diagram that shows the 3 components of the platform.
A simple pricing model in Snowflake
A virtual storage service has benefits alone. The data infrastructure is maintained for you, which means you don’t have to maintain your own servers, databases, and tools to manage it. The price for such a service will depend on the amount of memory required and the amount of computing capability to perform the queries.
Snowflake’s pricing model includes two components: the cost of storage and the cost of computing resources consumed. The charge for the consumption of computing resources is calculated on the basis of processing units, which we call credits. Credits used to run queries or to perform a service (e.g., loading data) are calculated according to the actual consumption per second.
Data warehouse configuration – how to make it according to your needs?
Before you start setting up your datastore in Snowflake, consider what size datastore you will need. If you are not sure what size will work for you then start with a smaller size. As new needs arise, slowly increase it depending on the performance and load you will need. An important factor in configuring Snowflake is determining the maximum number of clusters, that is, determining how many systems will be clustered together. As with size, it’s a good idea to choose a smaller amount and increase it based on your work with Snowflake and the loads generated.
Scaling in Snowflake
Scaling in Snowflake is done in the standard way, but if you want to queue the data you want to use then set it to “Economy” mode, this will save credits and the running data clusters will be fully loaded. Automatic job suspension is also important. The idea is that when there is no activity, the Snowflake data warehouse automatically determines the number of seconds with no activity, and the data warehouse operation is automatically suspended. The default value of no user work is set to 600 seconds, this means that the warehouse operation is suspended after 10 minutes of inactivity. If we know that the data load runs infrequently, it is a good idea to set the value to 60 seconds. Setting the value to NULL is not recommended due to significant credit consumption, especially when working on larger data stores.
In conclusion, if you need a flexible tool to store your data in the cloud, try Snowflake.


